Semantic Web Programming would allow searching the Semantics within programs rather than just outputs. This would be a step on from open source programming, this would allow open semantics programming. The code could then be visualised and interacted with using all the tools available for visualising semantic web languages. The whole tree/graph structure of a program could be visualised and searched easily.
Programming with XML is already enabled, and progress can now be made in using those languages such as RDF and OWL which are higher in the Semantic Web stack.
Programming with XML is possible using XForms, XQuery, Simkin, Metal, and many Rich Internet Application development environments.
Programming is becoming possible using OWL and OWL-S (OWL for Web Services). Visualisation of OWL structures enables editing by using UML Activity Diagrams, and OWL models programming structures such as if-then-else, and while loops.
Useful Links
Berners-Lee, T., Semantic Web - XML2000 - Architecture - http://www.w3.org/2000/Talks/1206-xml2k-tbl/slide10-0.html
Dmitriev, S., Jetbrains - Meta Programming System - http://www.onboard.jetbrains.com/is1/articles/04/10/lop/ - Language Oriented Programming: The Next Programming Paradigm - Sergey Dmitriev.
From BPEL4WS Process Model to Full OWL-S Ontology - http://www.eswc2006.org/poster-papers/FP13-Aslam.pdf - Muhammad Ahtisham Aslam, Sören Auer - University of Leipzig Germany, Jun Shen - University of Wollongong Australia - ABSTRACT - BPEL4WS is one of the most utilized business process development languages. It can be used to develop executable business processes as a combination of Web Services interactions in a specific sequence called process flow. But still BPEL4WS lacks sufficient representation of business process semantics required for business processes automation. On the other hand OWL-S (OWL for Web Services) is designed to present such kind of semantic information. There exists similarity in the conceptual model of OWL-S and BPEL4WS that can be used to overcome this lack of semantics in BEPL4WS by mapping the BPEL4WS process model to the OWL-S ontology. The mapped OWL-S service can be dynamically discovered, composed and invoked on the basis of matching semantics. Such a process of mapping syntax based Web Services composition in the form of BPEL process model to Semantic Web Services composition in the form of OWL-S composite service can also enable automation of BPEL processes as OWL-S services by applying AI planning techniques. In this paper we present a mapping strategy and a mapping tool that can be used to map BPEL processes to the OWL-S suite of ontologies.
Introduction to OWL - http://www.w3schools.com/rdf/rdf_owl.asp - OWL is a language for processing web information. What You Should Already Know Before you study OWL you should have a basic understanding of XML, XML Namespaces and RDF.
MetaL - http://www.meta-language.net/ - MetaL: An XML based Meta-Programming language.
OWL - http://www.cems.uwe.ac.uk/amrc/seeds/PeterHale/RDF/RDF.htmOWL
OWL-S API - http://www.mindswap.org/2004/owl-s/api/ - Mindswap - Maryland Information and Network Dynamics Lab Semantic Web Agents Project - OWL-S API provides a Java API for programmatic access to read, execute and write OWL-S (formerly known as DAML-S) service descriptions. The API supports to read different versions of OWL-S (OWL-S 1.0, OWL-S 0.9, DAML-S 0.7) descriptions. The API provides an ExecutionEngine that can invoke AtomicProcesses that has WSDL or UPnP groundings, and CompositeProcecesses that uses control constructs Sequence, Unordered, and Split. Executing processes that relies on conditionals such as If-Then-else and RepeatUntil is not supported in the default implementation. But this implementation can be extended to handle these constructs if the application that uses the OWL-S descriptions has a custom syntax and evaluation procedure for the conditions.
OWL-S Editor - http://owlseditor.semwebcentral.org/download.shtml - Download.
OWL-S Editor - http://iswc2004.semanticweb.org/demos/02/paper.pdf - Grit Denker and Daniel Elenius and David Martin - SRI International, California, USA, Linkoping University, Linkoping, Sweden - INTRODUCTION - An increasing number of organizations are endorsing Web Services (WS) technology to extend corporate resources to customers and partners and to leverage resources of others. AlthoughWeb Services, based on XML technology, allow interoperability, they do not support efficient and flexible search, allocation, composition, runtime monitoring, or invocation of those Web Services. Semantic Web Services (SWSs) use semantically rich annotations to facilitate these tasks. Richer semantics can provide fuller, more flexible automation of service provision, and use and support the construction of more powerful tools and methodologies.
OWL-S Editor to Semantically Annotate Web-Services - http://staff.um.edu.mt/cabe2/supervising/undergraduate/owlseditFYP/OwlSEdit.html - University of Malta - Department of Computer Science and A.I. - James Scicluna - The current version of the Owl-S Editor can be downloaded from here. We welcome any feedback related to how the tool was used and how effective it was to solve your particular needs. Let us know so that we can improve the tool.
OWL-S: Semantic Markup for Web Services - http://www.daml.org/services/owl-s/1.1/overview/ - Abstract - The Semantic Web should enable greater access not only to content but also to services on the Web. Users and software agents should be able to discover, invoke, compose, and monitor Web resources offering particular services and having particular properties, and should be able to do so with a high degree of automation if desired. Powerful tools should be enabled by service descriptions, across the Web service lifecycle. OWL-S (formerly DAML-S) is an ontology of services that makes these functionalities possible. In this document we describe the overall structure of the ontology and its three main parts: the service profile for advertising and discovering services; the process model, which gives a detailed description of a service's operation; and the grounding, which provides details on how to interoperate with a service, via messages.
OWL Web Ontology Language Guide - http://www.w3.org/TR/owl-guide/ - W3C Recommendation 10 February 2004 - The World Wide Web as it is currently constituted resembles a poorly mapped geography. Our insight into the documents and capabilities available are based ..word searches, abetted by clever use of document connectivity and usage patterns. The sheer mass of this data is unmanageable without powerful tool support. In order to map this terrain more precisely, computational agents require machine-readable descriptions of the content and capabilities of Web accessible resources. These descriptions must be in addition to the human-readable versions of that information.
The OWL-S Editor - A Development Tool for Semantic Web Services - http://owlseditor.semwebcentral.org/documents/paper.pdf - Daniel Elenius, Grit Denker, David Martin, Fred Gilham, John Khouri, Shahin Sadaati, and Rukman Senanayake - SRI International, Menlo Park, California, USA - Abstract. The power of Web Service (WS) technology lies in the fact that it establishes a common, vendor-neutral platform for integrating distributed computing applications, in intranets as well as the Internet at large. Semantic Web Services (SWSs) promise to provide solutions to the challenges associated with automated discovery, dynamic composition, enactment, and other tasks associated with managing and using service-based systems. One of the barriers to a wider adoption of SWS technology is the lack of tools for creating SWS specifications. OWL-S is one of the major SWS description languages. This paper presents an OWL-S Editor, whose objective is to allow easy, intuitive OWL-S service development and to provide a variety of special-purpose capabilities to facilitate SWS design. The editor is implemented as a plugin to the Protege OWL ontology editor, and is being developed as open-source software.
The OWL-S Editor - A Domain-Specific Extension to Protégé - Elenius, D., 2005. - 8th Intl. Protégé Conference - July 18-21, 2005 - Madrid, Spain.
Programming with XML - http://www.cems.uwe.ac.uk/amrc/seeds/PeterHale/XML/XML.htmProgrammingwithXML
Rich Internet Applications - http://www.cems.uwe.ac.uk/amrc/seeds/Ajax/ajax.htmRichInternetApplications
Simkin - http://www.simkin.co.uk/- A high-level lightweight embeddable scripting language which works with Java or C++ and XML.
VISUAL MODELING OF OWL-S SERVICES - http://members.deri.at/~jamess/pdfs/scicluna-iadis2004.pdf - Msida MSD 06, Malta (Europe) - Mr. James Scicluna, Mr. Charlie Abela, Dr. Matthew Montebello, Department of Computer Science and Artificial Intelligence, University of Malta - ABSTRACT - The Semantic Web is slowly gathering interest and becoming a reality. More people are becoming aware of this and are trying to embed Semantic Web technologies into their applications. This involves the use of tools that can handle rapid ontology building and validation in an easy and transparent manner. In the area of Semantic Web Web Services (SWWS) an OWL-S specification defines a set of ontologies through which a semantic description of the service can be created. At times this is not an easy task and could result in an incorrect specification of the description or even lead the fainthearted user to resort to some other type of description language. This paper describes the OWL-S editor tool that provides two methodologies in which such a web services description can be developed without exposing the developer to the underlying OWL-S syntax. These methodologies are based on a mapping from WSDL to OWL-S and on modeling a composite service using standard UML Activity Diagrams.
XForms - http://www.cems.uwe.ac.uk/amrc/seeds/Ajax/ajax.htmXForms
XQuery - http://www.cems.uwe.ac.uk/amrc/seeds/PeterHale/XML/XML.htmXQuery
Thursday, August 28, 2008
Wednesday, August 20, 2008
Semantic Web Interest Group - SWIG-UK event, Bristol UK
==== SWIG-UK - A Semantic Web Community Event
Hewlett-Packard Bristol
We would like to invite users and developers interested in the
semantic web to attend a community event to be held at HP Labs
Bristol, UK on Tuesday 11 November 2008. This will be an opportunity
for you to meet other users and developers and to share experiences
with semantic web applications.
The day will a mixture of discussion, demos, short presentations,
with a few longer presentations if offered. The objective is to
allow people to share experiences of using the semantic web. The
agenda will be driven by the attendees; it is not limited to Jena
applications nor limited to the UK.
Please register early so we know there is critical mass for the event.
Registration: swig-uk-2008@sparql.net
Further Information - http://groups.yahoo.com/group/semanticweb-southwest/ - Directions: http://www.hpl.hp.com/bristol/directions.html.
Tuesday, August 12, 2008
Meta-Programming as a Model Creation Technique
Model-Driven Programming and Meta-Programming together with Semantic Web and End-User Programming techniques are vital ingredients of the User Driven Programming/Modelling approach used in this thesis. Dmitriev (2006) explains the problem to be solved in order to improve model production as “limitations of programming which force the programmer to think like the computer rather than having the computer think more like the programmer.” Meta-programming (Dmitriev, 2006) is a useful way of allowing for language independent software development, and can aid in providing a high level front-end to programming languages. “Meta-programming is the writing of programs that write or manipulate other programs (or themselves) as their data” (Wikipedia, 2008).
The idea behind use of meta-programming in this thesis is that instead of writing programs to do a task a domain expert needs the program for, the meta program developer creates an environment which all domain experts, in this and similar fields can use to create their own solutions. The developer then only needs to maintain and improve this programming environment, and can concentrate on this task; the domain expert can concentrate on solving the problem at hand without having to ask the developer to create the code on his or her behalf. Dmitriev (2006) advocates reducing dependency on languages and environments by enabling programmers to develop their own specific languages for solving each domain problem:
"If we are going to make creating languages easy, we need to separate the representation and storage of the program from the program itself. We should store programs directly as a structured graph, since this allows us to make any extensions we like to the language. Sometimes, we wouldn't even need to consider text storage at all. A good example of this today is an Excel spreadsheet. Ninety-nine percent of people don't need to deal with the stored format at all, and there are always import and export features when the issue comes up. The only real reason we use text today is because we don't have any better editors than text editors. But we can change this... Text editors... don't know how to work with the underlying graph structure of programs. But with the right tools, the editor could work directly with the graph structure, and give us freedom to use any visual representation we like in the editor. We could render the program as text, tables, diagrams, trees, or anything else. We could even use different representations for different purposes, e.g. a graphical representation for viewing, and a textual representation for editing. We could use domain specific representations for different parts of the code, e.g. graphical math symbols for math formulas, graphic charts for charts, rows and columns for spreadsheets, etc. We could use the most appropriate representation for the problem domain, which might be text, but is not limited to text. The best representation depends on how we think about the problem domain. This flexibility of representation would also enable us to make our editors more powerful than ever, since different representations could have specialized ways to edit them."
This provides a way to create programs that create programs so enabling the 3 step translation process used in this thesis, and this enables translations between people, between systems, and between languages. This could enable those who are not currently programmers to create models at their domain level using domain specific systems created for them by programmers. The mechanisms for this are recursive translation of the tree/graph code representation to multiple models and languages, where necessary aided by user/modeller choices.
References
Dmitriev, S., 2007. Language Oriented Programming: The Next Programming Paradigm - http://www.onboard.jetbrains.com/is1/articles/04/10/lop/.
Fischer, G., 2007. 'Meta-Design: A Conceptual Framework for End-User Software Engineering' http://drops.dagstuhl.de/opus/frontdoor.php?source_opus=1087 - Dagstuhl Seminar Proceedings.
Wikipedia (2008) Metaprogramming - http://en.wikipedia.org/wiki/Metaprogramming.
More information is available at - http://www.cems.uwe.ac.uk/amrc/seeds/softwareengineering.htm#MetaProgramming.
The idea behind use of meta-programming in this thesis is that instead of writing programs to do a task a domain expert needs the program for, the meta program developer creates an environment which all domain experts, in this and similar fields can use to create their own solutions. The developer then only needs to maintain and improve this programming environment, and can concentrate on this task; the domain expert can concentrate on solving the problem at hand without having to ask the developer to create the code on his or her behalf. Dmitriev (2006) advocates reducing dependency on languages and environments by enabling programmers to develop their own specific languages for solving each domain problem:
"If we are going to make creating languages easy, we need to separate the representation and storage of the program from the program itself. We should store programs directly as a structured graph, since this allows us to make any extensions we like to the language. Sometimes, we wouldn't even need to consider text storage at all. A good example of this today is an Excel spreadsheet. Ninety-nine percent of people don't need to deal with the stored format at all, and there are always import and export features when the issue comes up. The only real reason we use text today is because we don't have any better editors than text editors. But we can change this... Text editors... don't know how to work with the underlying graph structure of programs. But with the right tools, the editor could work directly with the graph structure, and give us freedom to use any visual representation we like in the editor. We could render the program as text, tables, diagrams, trees, or anything else. We could even use different representations for different purposes, e.g. a graphical representation for viewing, and a textual representation for editing. We could use domain specific representations for different parts of the code, e.g. graphical math symbols for math formulas, graphic charts for charts, rows and columns for spreadsheets, etc. We could use the most appropriate representation for the problem domain, which might be text, but is not limited to text. The best representation depends on how we think about the problem domain. This flexibility of representation would also enable us to make our editors more powerful than ever, since different representations could have specialized ways to edit them."
This provides a way to create programs that create programs so enabling the 3 step translation process used in this thesis, and this enables translations between people, between systems, and between languages. This could enable those who are not currently programmers to create models at their domain level using domain specific systems created for them by programmers. The mechanisms for this are recursive translation of the tree/graph code representation to multiple models and languages, where necessary aided by user/modeller choices.
References
Dmitriev, S., 2007. Language Oriented Programming: The Next Programming Paradigm - http://www.onboard.jetbrains.com/is1/articles/04/10/lop/.
Fischer, G., 2007. 'Meta-Design: A Conceptual Framework for End-User Software Engineering' http://drops.dagstuhl.de/opus/frontdoor.php?source_opus=1087 - Dagstuhl Seminar Proceedings.
Wikipedia (2008) Metaprogramming - http://en.wikipedia.org/wiki/Metaprogramming.
More information is available at - http://www.cems.uwe.ac.uk/amrc/seeds/softwareengineering.htm#MetaProgramming.
Wednesday, August 06, 2008
Open Standard Representation of Rules and Equations
SWRL
Miller and Baramidze (2005) explain and SWRL (Semantic Web Rule Language). Zhao and Liu (2008) examine the need for sharing product information between partners as a product model, and how agreement through ontologies, Semantic Web, and standards can assist this. Zhao and Liu examine mapping of STEP representations to ontology languages OWL - http://www.cems.uwe.ac.uk/amrc/seeds/PeterHale/RDF/RDF.htm#OWL and SWRL and how this benefits interoperability. Zhao and Liu are encoding STEP rules and executable statements into OWL and SWRL. Zhao and Liu also show a diagram (similar to this one of Berners-Lee) of the position of OWL and SWRL in a stack of standards from XML in the Syntax layer up to OWL/SWRL in the Logic/Rule layer of 'Semantics'.
SWRL (Semantic Web Rule Language) combining OWL and RuleML and its use in modelling will also be investigated. This could be used for formally specifying the construction of equations and rules in a model and the relationships and constraints between items represented in an equation. Miller and Baramidze (2005) explain the SWRL language. An editing facility to model these equations and constraints, so that errors could be prevented, would improve the usability of future visual modelling systems created. Support for SWRL in Protégé and other ontology based systems will assist with the construction of a modelling system with sophisticated editing of rules (Miller and Baramidze, 2005). Miller and Baramidze (2005) examine efforts to develop mathematical semantic representations above the syntactical representations of MathML. SWRL also has standardised arithmetic and comparison operators (Zhao and Liu, 2008). These languages should enable standardisation of the representation of mathematical expressions that relate nodes, and their values and expressions; this would seem to be a difficult problem as it needs a user interface that enables complex mathematical structures to be conveyed by language and/or diagrammatic visualisation.
References
Miller, J A., Baramidze, G., Simulation and the Semantic Web - 2005. - Proceedings of the 2005 Winter Simulation Conference.
Zhao, W. and Liu, J.K. 2008. OWL/SWRL representation methodology for EXPRESS-driven product information model Part I. Implementation methodology, Computers in Industry - Article in Press, Corrected Proof - Abstract - This paper presents an ontology-based approach to enable semantic interoperability and reasoning over the product information model. The web ontology language (OWL) and the semantic web rule language (SWRL) in the Semantic Web are employed to construct the product information model. The traditional modeling language called EXPRESS is discussed. The representation methodology for EXPRESS-driven product information model is then proposed. The key of the representation methodology is mapping from EXPRESS to OWL/SWRL. Some illustrated examples are presented. - Keywords - Product information model; OWL; SWRL; EXPRESS; Ontology representation. Zhao and Liu (2008) are encoding STEP rules and executable statements into OWL and SWRL.
RuleML
The research of the Rule Markup Initiative is explained here. Rules for the Web have become a mainstream topic since inference rules became important in E-Commerce and the Semantic Web, and since transformation rules were put into practice for document generation from a central XML repository. Rules have continued to play an important role in artificial intelligence, knowledge-based systems, and for intelligent agents. This is now combined with standardisation in XML/RDF enabling use of declarative rules for web services. The Rule Markup Initiative has taken steps towards defining a shared Rule Markup Language (RuleML), enabling both forward (bottom-up) and backward (top-down) rules.
Reference
RuleML - The Rule Markup Initiative http://www.ruleml.org/.
Representation of Equations
Gruber (1993) examines how equations and quantities can be represented in an ontology. Kamareddine et al. (2004) examine how mathematics can be represented in order to make it easier for people to enter well-formed mathematical expressions.
Shim et al. (2002) examine translation from a users' model to equations and explain "converting a decision-makers' specification of a decision problem into an algebraic form and then into a form understandable by an algorithm is a key step in the use of a model". For a practical example the figure below explains the concept for a simple example of the representation of the equation E=MC2. This relationship can be defined by the user. Here this is achieved using an ontology tool (Protégé), and this definition can be read directly by Decision support software (Vanguard Studio) that can visualise the information and colour code it. For a more complex example a higher level user interface would be required to enable a user to define the problem, and a translation step to the computer readable model. Units have been left out as the type of equation used and values in it are not important to the concept. The software can translate the source model into a program and calculate results. The result program is then translated again into a result model defined using open standard languages such as XML, and Java for human friendly visualisations viewable as web pages/diagrams.

Translation Process - Equations
References
Gruber T. R. 1993, Toward Principles for the Design of Ontologies Used for Knowledge Sharing - http://www2.umassd.edu/SWAgents/agentdocs/stanford/onto-design.pdf - In Formal Ontology in Conceptual Analysis and Knowledge Representation, edited by Nicola Guarino and Roberto Poli, Kluwer Academic Publishers, in press. Substantial revision of paper presented at the International Workshop on Formal Ontology, March, 1993, Padova, Italy. Available as Technical Report KSL 93-04, Knowledge Systems Laboratory, Stanford University.
Kamareddine, F., Maarek, M., Wells, J. B, 2005, Toward an Object-Oriented Structure for Mathematical Text - http://www.macs.hw.ac.uk/~jbw/papers/Kamareddine+Maarek+Wells:Toward-an-Object-Oriented-Structure-for-Mathematical-Text:MKM-2005.pdf - Mathematical Knowledge Management, 4th Int'l Conf., Proceedings, LNCS. Springer-Verlag.
Quint, V., Vatton, I., 2004. Techniques for Authoring Complex XML Documents - http://wam.inrialpes.fr/publications/2004/DocEng2004VQIV.html - DocEng 2004 - ACM Symposium on Document Engineering Milwaukee October 28-30 - This paper reviews the main innovations of XML and considers their impact on the editing techniques for structured documents.
Quint, V., Vatton, I., 2005. Towards Active Web Clients - http://wam.inrialpes.fr/publications/2005/DocEng05-Quint.html - DocEng 2005 - ACM Symposium on Document Engineering - 2-4 November 2005 - Bristol, United Kingdom. - Recent developments of document technologies have strongly impacted the evolution of Web clients over the last fifteen years, but all Web clients have not taken the same advantage of this advance. In particular, mainstream tools have put the emphasis on accessing existing documents to the detriment of a more cooperative usage of the Web. However, in the early days, Web users were able to go beyond browsing and to get more actively involved.
Shim, J.P., Warkentin, M., Courtney, J. F., Power, D J., 2002, Past, present, and future of decision support technology - Decision Support Systems - Volume 33, Issue 2 , June 2002, Pages 111-126.
MathML
MathML is a specification for describing mathematics as a basis for machine to machine communication. It provides a way of including mathematical expressions in Web pages. This is explained at World Wide Web Consortium Math Home (2008). There is support for creation and editing of MathML documents in Amaya (Amaya, 2008), (Quint and Vatton, 2004 and 2005).
MathML and semantics built on this could assist in the process of translating equations/formulae into code by providing an open representation of functions as XML (eXtensible Markup Language). Functions entered by the model developer can then be translated to this open representation and translated to programming languages and/or read by programming languages.
Miller and Baramidze (2005) examine efforts to develop mathematical semantic representations above the syntactical representations of MathML.
References
Amaya - http://www.w3.org/Amaya/ - Welcome to Amaya - W3C's Editor/Browser - Amaya is a Web editor, i.e. a tool used to create and update documents directly on the Web. Browsing features are seamlessly integrated with the editing and remote access features in a uniform environment. This follows the original vision of the Web as a space for collaboration and not just a one-way publishing medium.
Miller, J A., Baramidze, G., Simulation and the Semantic Web - 2005. - Proceedings of the 2005 Winter Simulation Conference.
World Wide Web Consortium (W3C) Math Home, 2008. What is MathML? http://www.w3.org/Math/Overview.html.
Links
Coq proof assistant - http://coq.inria.fr/ - Coq is a formal proof management system: a proof done with Coq is mechanically checked by the machine.
End User Programming for Scientists: Modeling Complex Systems - http://drops.dagstuhl.de/opus/volltexte/2007/1077/ - Andrew Begel - Microsoft Research - In: End-User Software Engineering - Dagstuhl Seminar - Summary - http://www.dagstuhl.de/en/program/calendar/semhp/?semnr=2007081 - Margaret M. Burnett, Gregor Engels, Brad A. Myers and Gregg Rothermel - From 18.01.07 to 23.02.07, the Dagstuhl Seminar 07081 End-User Software Engineering was held in the International Conference and Research Center (IBFI), Schloss Dagstuhl.
EquMath.Net - http://equmath.net/ - EquMath is resource for math lessons from Algebra to Differential Equations!.
Equplus - http://equplus.net/ - Science and Math Equations.
Mathematica - http://www.wolfram.com/ - Wolfram Research.
Mathematical Functions - Interactive Graph - http://www.richtann.com/2dExamples/graph.html - Richard Tann UWE - An Example using Actionscript to model functions and dynamically redraw according to user interaction.
MathLang: experience-driven development of a new mathematical language - http://citeseer.ist.psu.edu/kamareddine04mathlang.html - F. Kamareddine, et al., 2004 - Abstract: In this paper we report on the design of a new mathematical language and our method of designing it, driven by the encoding of mathematical texts. MathLang is intended to provide support for checking basic well-formedness of mathematical text without requiring the heavy and dicult-to-use machinery of full type theory or other forms of full formalization. At the same time, it is intended to allow the addition of fuller formalization to a document as time and e ort permits.
MathWeb - http://www.mathweb.org/ - MathWeb.org supplies an infrastructure for web-supported mathematics.
Mizar Project - http://mizar.org/project/ - The Mizar project started around 1973 as an attempt to reconstruct mathematical vernacular in a computer-oriented environment.
OMDoc.org - http://www.omdoc.org/ - OMDoc.org: The OMDoc Portal - OMDoc is a markup format and data model for Open Mathematical Documents. It serves as semantics-oriented representation format and ontology language for mathematical knowledge.
OpenMath - http://www.openmath.org/ - OpenMath is a new, extensible standard for representing the semantics of mathematical objects.
Richard Tann UWE - http://www.richtann.com/2dExamples/graph.html - Mathematical Functions - An Example using Actionscript to model functions and dynamically redraw according to user interaction.
Toward an Object-Oriented Structure for Mathematical Text - http://www.macs.hw.ac.uk/~jbw/papers/Kamareddine+Maarek+Wells:Toward-an-Object-Oriented-Structure-for-Mathematical-Text:MKM-2005.pdf - Kamareddine, F., Maarek, M., Wells, J. B, 2005, Mathematical Knowledge Management, 4th Int'l Conf., Proceedings, LNCS. Springer-Verlag.
SRML
SRML - Simulation Reference Markup Language - http://www.w3.org/TR/SRML/ - W3C Note 18 December 2002.
SRML case study: simple self-describing process modeling and simulation - http://ieeexplore.ieee.org/xpls/abs_all.jsp?arnumber=1371486 - Reichenthal, S.W. Boeing, Anaheim, CA, USA; 2004, Simulation Conference, 2004. Proceedings of the 2004 Winter - Volume: 2, pp 1461- 1466 - ISBN: 0-7803-8786-4.
Wednesday, July 30, 2008
End User Programming, Modelling and the Semantic Web
This diagram shows the research direction this thesis moved in over time.
- End-user programming for modelling. Research began with examining programming needs of users (mainly engineers at Airbus and later Rolls-Royce aerospace companies).
- Modelling – Next, models were created to cater for the engineers needs for prediction and decision support; so the concentration was mainly on modelling.
- Semantic Web for modelling. Once the models became more complex and numerous, the collaboration necessary required a more systematic infrastructure, so Semantic Web and ontology research assisted with this.
- Semantic Web for end-user programming. Once an infrastructure was prototyped it was possible to research how this could enable construction of programs based on the Semantic Web/ontology infrastructure.
- Programs created using the semantic web infrastructure and visual diagrammatic programming were tested for modelling capability.

Research Direction Spiral
By the end of this research it was perceived that this particular combination as indicated by the mid point of the yellow section was currently under researched by the wider community.
More information is available at - http://www.cems.uwe.ac.uk/~phale/#ResearchAim.
Wednesday, July 23, 2008
Semantic Web Event
This Semantic Web event is being organised by Daniel Lewis, details are below -
Friday 5th September 2008
Time: 14:00 - 18:00
Bristol Knowledge Unconference -
Location: eOffice Bristol, 1st Floor Prudential Buildings, 11-19 Wine Street Bristol, BS1 2PH.
A few more bits of information are available at:
http://vanirsystems.com/danielsblog/2008/07/22/date-set-for-bristol-knowledge-unconference/.
You can sign up for the event at:
http://knowledgeunconference.eventwax.com/bristol-knowledge-unconference.
Further information -
Daniel Lewis - Bristol Knowledge Unconference: A small progress update - http://vanirsystems.com/danielsblog/2008/07/15/bristol-knowledge-unconference-a-small-progress-update/ -
http://vanirsystems.com/danielsblog/2008/07/10/bristol-knowledge-unconference/
Daniel Lewis - I am organising a "Knowledge Unconference" in Bristol, which is loosely attached to the "Semantic Web South-West" Group.
The idea will be similar to a BarCamp, except that it is a lot lighter, more social, more hands-on. It will also be only half-a-day long. Plus it will be "themed" around the general subject of Knowledge. So for example:
The Semantic Web / Linked Data / Hyperdata / Data Web
Topic Maps
Information Architecture and Design
Knowledge Acquisition
Knowledge-Based Systems, Knowledge Engineering and Rule-Based Systems (etc)
Knowledge Visualisation
and maybe even, Object Oriented Databases
Tuesday, July 15, 2008
Semantic Web and End-User Programming
Semantic Web research is not an end in itself as without the combination with End-User Programming/Modelling in order that people can create programs; there is insufficient incentive for creation and use of Semantic Web information. The reverse of this combination is that end-user modelling/programming is not practical without creation and use of structured information available through an accessible interface, such as representations using the Semantic Web.
My research area is explained here http://www.cems.uwe.ac.uk/~phale/#LanguageToolMapping :-
My research area is explained here http://www.cems.uwe.ac.uk/~phale/#LanguageToolMapping :-

The representation of program structure also needs to be visualised to End-User Programmers so they can create and edit content.
In order to increase the use of Semantic Web technologies it is necessary to create applications that make use of the Semantic Web for practical applications. Enabling modelling with Semantic Web technologies could encourage domain experts to fill ontologies with useful information, so generating more benefit from their use.
Monday, June 30, 2008
Visualisation and Interaction for Modelling
Eng and Salustri (2006) outline the role of computers in aiding decision making, and explain that the human mind is the best tool for making decisions. They explain that visualisation systems must help people use the information access capabilities of computers. Eng and Salustri refer to a dimension from “tacit to articulatable” knowledge. So the research for this thesis aims to use the layered Semantic architecture described by Berners Lee et al. (2000) and discussed by McGuinness (2003) relating to this diagram :-
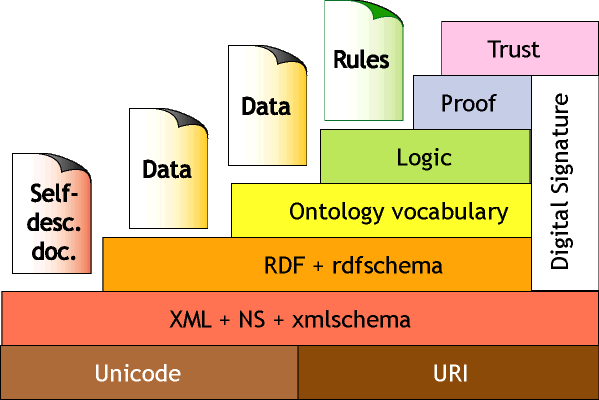
Layered Architecture, sourced from McGuinness (2003) and Berners-Lee (2000)
This improves translatation between the layers to enable human/computer translation. This approach is intended to improve interaction rather than enable computing decision making through artificial intelligence; the emphasis is on decision support for design and manufacture. The detail of this approach and the methodology for automating translation for users is explained in here - http://www.cems.uwe.ac.uk/~phale/#ResearchMethodology. Such techniques as genetic algorithms are outside the scope of this thesis. Instead the emphasis is on clear visualisation, interaction and translation.
This translation code reproduces a taxonomy/ontology and makes it available for modelling/programming systems. This taxonomy/ontology is a copied subset of the main ontology produced as an instance of the main ontology according to model builder choices and for the modelling/programming purposes of that model builder.

Recursive Translation - Automated Copying from ontology to modelling system
Also the translation can link different ontologies/taxonomies together when they are required in order to solve a problem. So the approach is to gather information from ontologies/taxonomies as required for solving a problem as specified by the model builder. This is tested and applied to engineering modelling. An open source approach can be combined with use of open standards ontologies as was advocated by Cheung (2005).
References
Berners-Lee, T., (2000) Semantic Web on XML – Slide 10 [online]. Available from: http://www.w3.org/2000/Talks/1206-xml2k-tbl/slide1-0.html [Accessed 26 June 2008].
Cheung, W. M., Maropoulos, P. G., Gao, J. X., Aziz, H., 2005. Ontological Approach for Organisational Knowledge Re-use in Product Developing Environments. In: 11th International Conference on Concurrent Enterprising - ICE 2005, University BW Munich, Germany.
Eng, N., Salustri, F. A., 2006. "Rugplot" Visualization for Preliminary Design. In: CDEN 2006 3rd CDEN/RCCI International Design Conference University of Toronto, Ontario, Canada.
McGuinness D. L., 2003. Ontologies Come of Age. In: Dieter Fensel, Jim Hendler, Henry Lieberman, and Wolfgang Wahlster, ed. Spinning the Semantic Web: Bringing the World Wide Web to Its Full Potential. MIT Press, 2003 [online]. Available from: http://www-ksl.stanford.edu/people/dlm/papers/ontologies-come-of-age-mit-press-(with-citation).htm [Accessed 26 June 2008].
Layered Architecture, sourced from McGuinness (2003) and Berners-Lee (2000)
This improves translatation between the layers to enable human/computer translation. This approach is intended to improve interaction rather than enable computing decision making through artificial intelligence; the emphasis is on decision support for design and manufacture. The detail of this approach and the methodology for automating translation for users is explained in here - http://www.cems.uwe.ac.uk/~phale/#ResearchMethodology. Such techniques as genetic algorithms are outside the scope of this thesis. Instead the emphasis is on clear visualisation, interaction and translation.
This translation code reproduces a taxonomy/ontology and makes it available for modelling/programming systems. This taxonomy/ontology is a copied subset of the main ontology produced as an instance of the main ontology according to model builder choices and for the modelling/programming purposes of that model builder.
Recursive Translation - Automated Copying from ontology to modelling system
Also the translation can link different ontologies/taxonomies together when they are required in order to solve a problem. So the approach is to gather information from ontologies/taxonomies as required for solving a problem as specified by the model builder. This is tested and applied to engineering modelling. An open source approach can be combined with use of open standards ontologies as was advocated by Cheung (2005).
References
Berners-Lee, T., (2000) Semantic Web on XML – Slide 10 [online]. Available from: http://www.w3.org/2000/Talks/1206-xml2k-tbl/slide1-0.html [Accessed 26 June 2008].
Cheung, W. M., Maropoulos, P. G., Gao, J. X., Aziz, H., 2005. Ontological Approach for Organisational Knowledge Re-use in Product Developing Environments. In: 11th International Conference on Concurrent Enterprising - ICE 2005, University BW Munich, Germany.
Eng, N., Salustri, F. A., 2006. "Rugplot" Visualization for Preliminary Design. In: CDEN 2006 3rd CDEN/RCCI International Design Conference University of Toronto, Ontario, Canada.
McGuinness D. L., 2003. Ontologies Come of Age. In: Dieter Fensel, Jim Hendler, Henry Lieberman, and Wolfgang Wahlster, ed. Spinning the Semantic Web: Bringing the World Wide Web to Its Full Potential. MIT Press, 2003 [online]. Available from: http://www-ksl.stanford.edu/people/dlm/papers/ontologies-come-of-age-mit-press-(with-citation).htm [Accessed 26 June 2008].
Monday, June 16, 2008
User Driven Modelling - Intermediate Benefits
Although User Driven Modelling/Programming is a difficult problem and only partially solved, there are numerous intermediate benefits from the search for this approach. These include better modelling and visualisation of problems, improved interaction with end-users, Semantic Web modelling search and visualisation methods, collaboration to improve modelling, and ways to agree ontology and Semantic Web representations. It was necessary to provide such intermediate benefits as the industrial collaborators had shorter term goals and so required deliverables.
The techniques used helped with progress towards improved interoperability that can aid in all the above areas. These uses and improved interoperability to support them needed to be developed together in an iterative way.
Experienced programmers/software engineers may have many of the problems of end-user programmers whenever they need to use a language/system they are unfamiliar with, or when the language/system they use is updated to a new version. So this means the techniques and approach developed can aid experienced software developers in such circumstances, as well as end-user programmers.
The techniques used helped with progress towards improved interoperability that can aid in all the above areas. These uses and improved interoperability to support them needed to be developed together in an iterative way.
Experienced programmers/software engineers may have many of the problems of end-user programmers whenever they need to use a language/system they are unfamiliar with, or when the language/system they use is updated to a new version. So this means the techniques and approach developed can aid experienced software developers in such circumstances, as well as end-user programmers.
Friday, June 06, 2008
Research Development
It is important to enable changes to the design of the information source and its structure as necessary, even when it contains information. This makes possible continuous improvement of the information and its representation together. Clear visualisation of the structure makes out of date and duplicate information obvious, so it can be changed by the end-users of the information. This provides for maintenance of information quality without necessitating end-users to understand relational database design; though relational databases can still be used for information where the frequency of structural change is less.
The diagrams below shows the way iterative development is used both in this research and in the implementation to ensure that changes can be made systematically as necessary and without disrupting the project.

Research and Development for Thesis
Information about my Research is at - http://www.cems.uwe.ac.uk/~phale/.
Friday, May 30, 2008
Visual Diagrammatic Programming
With visual diagrammatic modelling it was possible to include one model within another as a software component, and demarcate responsibility for building, maintenance, and updating of each model. This was difficult using spreadsheets, and possible with non-visual programming though the link between individual responsibilities and code produce was not as clearly identified, because non-programmers cannot participate in code production. As an example, for cost modelling of an aircraft wing, different experts might build software models for wing spars, wing skins etc, and another expert might be responsible for the overall wing cost model. The wing spar and skins model would then be inserted into the overall wing cost model.
The techniques demonstrated in this thesis can aid progress towards accessing of data held using Semantic Web standards, and also other information that might be locked into particular systems such as databases, spreadsheets and enterprise systems. The translation and de-abstraction approach assists with enabling high level diagrammatic visualisations to be used and translated to computer queries. Programming using Semantic Web technologies can :-
* Assist with translating non-Semantic Web information into Semantic Web information.
* Assist in production of Semantic Web information by end-users by.
* Assist end-users to query non-Semantic Web information.
Further Visualisation Information is at - http://www.cems.uwe.ac.uk/amrc/seeds/Visualisation.htm
End User Programming Information is at - http://www.cems.uwe.ac.uk/amrc/seeds/EndUserProgramming.htm
Thursday, May 22, 2008
Drag and Drop Visual Programming
2 main conclusions resulted from examining the history of end-user computing :-
• Research that created prototype systems for specialist users, school children, and other researchers and programmers, but failed to take make headway in the mass market can be reused with more up to date technology to assist development.
• More pragmatic research that involved creation of tools for the mass market, but which avoided more long term research issues can now be extended.
One mechanism for applying new technologies for use in end-user programming is drag and drop programming.
Repenning (2007) explains the need for enhancements to UML to aid end-user programming. Repenning also argues that "Visual programming languages using drag and drop mechanisms as the programming approach makes it virtually impossible to create syntactic errors." So "With the syntactic challenge being - more or less - out of the way we can focus on the semantic level of End-User Programming." This can make a high level model driven approach to production of better models possible. Rosson (2007) also explains about creation of a web-based drag and drop interface.
Ways that research is pursued in this thesis in order to make User Driven Programming possible are:-
1. Semantic Web and Web 2.0 approach to enabling User Generated Content.
2. User Centric Extensions to UML (Unified Modelling Language) e.g. (Vernazza, 2007) this approach also ventures into 1 and 3).
3. Visual Programming Extensions to spreadsheet type formulae based modelling enabled using approach 1.
Approach 1 is illustrated by Yahoo Pipes (2008) which provides for drag and drop editing of visual components that can combine, sort, and filter RSS data sources in order to automate web application development. This enables modelling of information, and using such diagrammatic programming combined with enabling of calculations would combine these three ways of producing applications. Yahoo Pipes enables creation of modelling applications with Semantic Web information, so this could assist in providing more incentive for provision of Semantic Web information and applications to use it.
So there is considerable overlap between these three approaches and they must be integrated within interdisciplinary research to enable user driven programming. One approach to this is a Semantic User Interface; this is explained in Vernazza (2007). This can enable Drag and Drop programming that combines the benefits of all three research approaches. The important factor is to connect the user interface with the underlying code, so the two share the same structure and users can properly see how their actions can change the actual code. This enables collaborative User-Driven programming.
References
Pipes and Filters for the Internet - http://radar.oreilly.com/archives/2007/02/pipes-and-filters-for-the-inte.html - O'Reilly - Feb 7 2007 - Yahoo!'s new Pipes service is a milestone in the history of the internet. It's a service that generalizes the idea of the mashup, providing a drag and drop editor that allows you to connect internet data sources, process them, and redirect the output.
Repenning, A., 2007. End-User Design. In: End-User Software Engineering Dagstuhl Seminar.
Rosson, M. B., 2007. Position paper for EUSE 2007 at Dagstuhl. In: End-User Software Engineering Dagstuhl Seminar.
Vernazza, L., 2007. Himalia: Model-Driven User Interfaces Using Hypermedia, Controls and Patterns In: IFAC/IFIP/IFORS IEA Symposium - Analysis, Design, and Evaluation of Human-Machine Systems Seoul, Korea - September 4-6th 2007 - International Federation of Automatic Control.
Yahoo Pipes [online]. Available from: http://pipes.yahoo.com/pipes/ [Accessed May 22nd 2008].
This is a Yahoo Pipes example created for the subject of Web 2.0/AJAX -
Yahoo Pipes RSS Feed for Web 2.0 - http://pipes.yahoo.com/pipes/pipe.info?_id=3e30625ebd44f24ff969ae5eef724425
An explanation of how to access and use the pipe created from a web page is at - Code Explanataion/Tutorial Freshblog - Blogger Hacks, Categories, Tips & Tricks - http://blogfresh.blogspot.com/2007/03/pipes-json-and-code-for-your-website.html.
Another article I wrote on Drag and Drop programming is at http://ezinearticles.com/?Drag-and-Drop-Programming&id=671578 and information and examples at http://www.cems.uwe.ac.uk/amrc/seeds/Ajax/ajax.htm#DragandDropProgramming
Tuesday, May 13, 2008
Semantic Web Collaboration
There is a need for Semantic Web applications in order to increase the amount of Semantic Web information that can be searched. This could result in a virtuous circle of Semantic Web applications creating Semantic Web information, and so justifying the creation of more Semantic Web applications to access it. This research advocates the use of Semantic Web applications for modelling and end-user programming, and integration into business applications.
Research in the use and visualisation of Semantic Web information can provide the tools that end-user programmers have been lacking until recently, and these tools can be used for modelling. A modelling environment needs to be created by software developers in order to allow users/model builders/domain experts to create collaborative and interoperable models. This modelling environment could be created using an open standard language such as XML (eXtensible Markup Language). Cheung et al. (2005) demonstrate the importance of XML for interoperability and knowledge re-use. As the high (user) level translation, this would depend on tools developed in order to assist the user, provide an interface and manage the user interface. These tools are written by developers using lower level languages, in order to enable modelling by end-user modellers.
The use of Semantic Web languages as programming languages would assist greatly with interoperability as these languages are standardised for use in a wide range of computer systems (as explained by Berners-Lee and Fischetti (1999). Anderson's (2007) Joint Information Systems Committee (JISC) report explains that as an application becomes more popular, more people use it in order to communicate with others who use it. This enables exposing information using web technology, for re-use.
Anderson (2007) in a Joint Information Systems Committee (JISC) report explains how Semantic Web and Web 2.0 are related as Berners-Lee's intention in the early development of Semantic Web technologies was for pages to be interactive. Anderson's JISC report talks of Web 2.0 trends towards the "End of the software release cycle, Lightweight programming models, Software above the level of a single device, and Rich user experiences". The ontology development problem should be aided by publishing the ontology and allowing tagging of content by users, the advantages of this in creating a shared understanding of what things mean is explained by Anderson. Anderson explains that tagging by web users can generate some understanding and agreement about terms and an improved search facility, even without a formal ontology, or as a way to assist in the development and improvement of an ontology. Anderson's JISC report explains how the technologies used are enabling user-centred web applications, and the use of the web as a development platform. It explains "As a Web 2.0 concept, this idea of opening up goes beyond the open source software idea of opening up code to developers, to opening up content production to all users and exposing data for re-use and combination". Anderson (2007) establishes the need for communities to build ontologies. Software applications are needed that allow users with little software knowledge to edit and update ontologies themselves. Anderson talks of 'harnessing collective intelligence' by means of interactive collaborative software, he calls this 'distributed human intelligence'. Cayzer (2004) argues for provision of mechanisms to allow web page creators to tag their pages easily and as a natural part of the page creation. Al-Khalifa and Davis (2006) and Schmitz (2006) use this approach of user tagging combined with centralised ontology development.
Sternemann and Zelm (1999) explained that it has become necessary to research collaborative modelling and visualisation tools, because of the business trend towards global markets and decentralised organisation structures. Green et al. (2007), and Cheung et al. (2007) also explain this. So it is important to demonstrate a system that could be used to solve this problem by means of accessible, interoperable collaborative software to enable visual modelling/programming.
References
Al-Khalifa, H. S., Davis, H. C., 2006. Harnessing the Wisdom of Crowds: How To Semantically Annotate Web Resource Using Folksonomies. In: Proceedings of IADIS Web Applications and Research (WAR2006).
Anderson, P. Technology and Standards Watch. 2007. JISC (Joint Information Systems Committee) What is Web 2.0? Ideas, technologies and implications for education.
Berners-Lee, T., Fischetti, M., 1999. Weaving the Web. Harper San Francisco; Paperback: ISBN:006251587X
Cayzer, S., 2004. Semantic Blogging and Decentralized knowledge Management. Communications of the ACM. Vol. 47, No. 12, Dec 2004, pp. 47-52. ACM Press.
Cheung, W. M., Maropoulos, P. G., Gao, J. X., Aziz, H., 2005. Ontological Approach for Organisational Knowledge Re-use in Product Developing Environments. In: 11th International Conference on Concurrent Enterprising - ICE 2005, University BW Munich, Germany.
Cheung, W. M., Matthews, P. C., Gao, J. X., Maropoulos, P. G., 2007. Advanced product development integration architecture: an out-of-box solution to support distributed production networks. International Journal of Production Research March 2007.
Green, S., Beeson, I., Kamm, R., 2007. Process architectures and process models: opportunities for reuse. In: 8th Workshop on Business Process Modeling, Development, and Support BPMDS07 and CAiSE'07 11-15 June 2007, Trondheim, Norway.
Schmitz, P., 2006. Inducing ontology from Flickr tags. In: WWW2006 Conference, Edinburgh, UK. May 22-26, 2006.
Sternemann, K. H., Zelm, M., 1999. Context sensitive provision and visualisation of enterprise information with a hypermedia based system, Computers in Industry Vol 40 (2) pp 173-184.
More Information on this subject is available at - http://www.cems.uwe.ac.uk/amrc/seeds/Ajax/ajax.htm.
My Research - http://www.cems.uwe.ac.uk/~phale/.
Modelling - http://www.cems.uwe.ac.uk/amrc/seeds/Modelling.htm.
Research in the use and visualisation of Semantic Web information can provide the tools that end-user programmers have been lacking until recently, and these tools can be used for modelling. A modelling environment needs to be created by software developers in order to allow users/model builders/domain experts to create collaborative and interoperable models. This modelling environment could be created using an open standard language such as XML (eXtensible Markup Language). Cheung et al. (2005) demonstrate the importance of XML for interoperability and knowledge re-use. As the high (user) level translation, this would depend on tools developed in order to assist the user, provide an interface and manage the user interface. These tools are written by developers using lower level languages, in order to enable modelling by end-user modellers.
The use of Semantic Web languages as programming languages would assist greatly with interoperability as these languages are standardised for use in a wide range of computer systems (as explained by Berners-Lee and Fischetti (1999). Anderson's (2007) Joint Information Systems Committee (JISC) report explains that as an application becomes more popular, more people use it in order to communicate with others who use it. This enables exposing information using web technology, for re-use.
Anderson (2007) in a Joint Information Systems Committee (JISC) report explains how Semantic Web and Web 2.0 are related as Berners-Lee's intention in the early development of Semantic Web technologies was for pages to be interactive. Anderson's JISC report talks of Web 2.0 trends towards the "End of the software release cycle, Lightweight programming models, Software above the level of a single device, and Rich user experiences". The ontology development problem should be aided by publishing the ontology and allowing tagging of content by users, the advantages of this in creating a shared understanding of what things mean is explained by Anderson. Anderson explains that tagging by web users can generate some understanding and agreement about terms and an improved search facility, even without a formal ontology, or as a way to assist in the development and improvement of an ontology. Anderson's JISC report explains how the technologies used are enabling user-centred web applications, and the use of the web as a development platform. It explains "As a Web 2.0 concept, this idea of opening up goes beyond the open source software idea of opening up code to developers, to opening up content production to all users and exposing data for re-use and combination". Anderson (2007) establishes the need for communities to build ontologies. Software applications are needed that allow users with little software knowledge to edit and update ontologies themselves. Anderson talks of 'harnessing collective intelligence' by means of interactive collaborative software, he calls this 'distributed human intelligence'. Cayzer (2004) argues for provision of mechanisms to allow web page creators to tag their pages easily and as a natural part of the page creation. Al-Khalifa and Davis (2006) and Schmitz (2006) use this approach of user tagging combined with centralised ontology development.
Sternemann and Zelm (1999) explained that it has become necessary to research collaborative modelling and visualisation tools, because of the business trend towards global markets and decentralised organisation structures. Green et al. (2007), and Cheung et al. (2007) also explain this. So it is important to demonstrate a system that could be used to solve this problem by means of accessible, interoperable collaborative software to enable visual modelling/programming.
References
Al-Khalifa, H. S., Davis, H. C., 2006. Harnessing the Wisdom of Crowds: How To Semantically Annotate Web Resource Using Folksonomies. In: Proceedings of IADIS Web Applications and Research (WAR2006).
Anderson, P. Technology and Standards Watch. 2007. JISC (Joint Information Systems Committee) What is Web 2.0? Ideas, technologies and implications for education.
Berners-Lee, T., Fischetti, M., 1999. Weaving the Web. Harper San Francisco; Paperback: ISBN:006251587X
Cayzer, S., 2004. Semantic Blogging and Decentralized knowledge Management. Communications of the ACM. Vol. 47, No. 12, Dec 2004, pp. 47-52. ACM Press.
Cheung, W. M., Maropoulos, P. G., Gao, J. X., Aziz, H., 2005. Ontological Approach for Organisational Knowledge Re-use in Product Developing Environments. In: 11th International Conference on Concurrent Enterprising - ICE 2005, University BW Munich, Germany.
Cheung, W. M., Matthews, P. C., Gao, J. X., Maropoulos, P. G., 2007. Advanced product development integration architecture: an out-of-box solution to support distributed production networks. International Journal of Production Research March 2007.
Green, S., Beeson, I., Kamm, R., 2007. Process architectures and process models: opportunities for reuse. In: 8th Workshop on Business Process Modeling, Development, and Support BPMDS07 and CAiSE'07 11-15 June 2007, Trondheim, Norway.
Schmitz, P., 2006. Inducing ontology from Flickr tags. In: WWW2006 Conference, Edinburgh, UK. May 22-26, 2006.
Sternemann, K. H., Zelm, M., 1999. Context sensitive provision and visualisation of enterprise information with a hypermedia based system, Computers in Industry Vol 40 (2) pp 173-184.
More Information on this subject is available at - http://www.cems.uwe.ac.uk/amrc/seeds/Ajax/ajax.htm.
My Research - http://www.cems.uwe.ac.uk/~phale/.
Modelling - http://www.cems.uwe.ac.uk/amrc/seeds/Modelling.htm.
Tuesday, May 06, 2008
Semantic Web Applications
In order to increase the use of Semantic Web technologies it is necessary to create applications that make use of the Semantic Web for practical applications. Enabling Modelling with Semantic Web technologies could encourage domain experts to fill ontologies with useful information, so generating more benefit from their use.
The use of Semantic Web languages as information representation and even as programming languages would assist greatly with interoperability as these modelling languages are standardised for use in a wide range of computer systems.
Research can bring together End-User Programming, Modelling and the Semantic Web approaches, so the shaded area is examined.
A methodology that involves structuring of information through Ontology and Semantic Web techniques and enabling end-user programming through visualisation and interaction aims to achieve effective production of generic models. Horrocks (2002) explains Semantic Web technologies and the use of agents and ontologies, and ontology representation languages. This demonstrates the linked nature of Ontology and Semantic Web research.
Berners-Lee and Fischetti (1999) sum up the advantage of a Semantic Web program over programs in other languages. They write, "The advantage of putting the rules in RDF is that in doing so, all the reasoning is exposed, whereas a program is a black box: you don't see what happens inside it." They discuss the use of Semantic Web languages as programming languages and explain the benefits declaring "The Semantic Web, like the Web already, will make many things previously impossible just obvious. Visual Semantic Web programming is one of those obvious things".
Berners-Lee et al. (2006) explain the importance of visualisation for navigation of information "Despite excitement about the Semantic Web, most of the world's data are locked in large data stores and are not published as an open Web of inter-referring resources. As a result, the reuse of information has been limited. Substantial research challenges arise in changing this situation: how to effectively query an unbounded Web of linked information repositories, how to align and map between different data models, and how to visualise and navigate the huge connected graph of information that results." The use of Semantic Web languages as programming languages would assist greatly with interoperability as these languages are standardised for use in a wide range of computer systems
The main advantage of open standard representation of information provided by the Semantic Web is that information can be transferred from one application to another. Additionally it provides a layered architecture that allows for a stepped translation from users to computer and back for conveying results of a modelling run. The program transformation approach argued for by Lieberman (2007) can be used to translate from a domain expert End-User Programmer abstraction to models represented by Semantic Web languages, ontologies and code.
Use of Semantic Web technologies is a means for open standard representation of collaborative models, transformation into different representations as required, and for provision of a high-level interface as a tool for model visualisation and system creation. Structuring of information through Ontology and Semantic Web techniques and enabling End-User Programming through visualisation and interaction can achieve effective production of generic models. Semantic Web technologies could assist greatly with Web based Simulation and Modelling. Kuljis and Paul (2001) evaluate progress in the field of web simulation. They argue the need for web-based simulations to be focussed on solving real-world problems in order to be successful. Miller and Baramidze (2005) establish that for a "simulation study that includes model building, scenario creation, model execution, output analysis and saving/interpreting results. Ontologies can be useful during all of these phases." Model-Driven Programming and the Semantic Web are explained by Frankel et al. (2004).
Research in the use and visualisation of Semantic Web information can provide the tools that end-user programmers have been lacking until recently, and these tools can be used for modelling. Crapo et al. (2002) assert the need for a methodology for creation of systems to enable more collaborative approaches to modelling by domain expert end-users, and that this combined with visualisation would allow engineers to model problems accurately.
Many organisations produce text based reports from their IT systems. But text based reports do not always show information well enough for good decision making. Automated conversion of these reports into Semantic Web languages could assist greatly with this. So a translation process is required and can be implemented as part of an overall User-Driven Modelling/Programming Approach. Once reports are converted to a standardised representation, hierarchical information can be represented as clickable trees and numerical representation as charts. This makes it possible to customise outputs from existing IT systems and so allows an improvement in readability of information without major changes to the way it's produced. This could provide a large gain at little cost.
References
Berners-Lee, T., Fischetti, M., 1999. Weaving the Web. Harper San Francisco; Paperback: ISBN:006251587X
Berners-Lee, T., Hall, W., Hendler, J., Shadbolt, N., Weitzner, D. J., 2006. Creating a Science of the Web. Science 11 August 2006:Vol. 313. no. 5788, pp. 769 - 771.
Crapo, A. W., Waisel, L. B., Wallace, W. A., Willemain, T. R., 2002. Visualization and Modelling for Intelligent Systems. In: C. T. Leondes, ed. Intelligent Systems: Technology and Applications, Volume I Implementation Techniques, 2002 pp 53-85.
Frankel, D., Hayes, P., Kendall, E., McGuinness, D., 2004. The Model Driven Semantic Web. In: 1st International Workshop on the Model-Driven Semantic Web (MDSW2004) Enabling Knowledge Representation and MDA® Technologies to Work Together.
Horrocks, I., 2002. DAML+OIL: a Reason-able Web Ontology Language. In: proceedings of the Eighth Conference on Extending Database Technology (EDBT 2002) March 24-28 2002, Prague.
Kuljis, J., Paul, R. J., 2001. An appraisal of web-based simulation: whither we wander?. Simulation Practice and Theory, 9, pp 37-54.
Lieberman, H., 2007. End-User Software Engineering Position Paper. End-User Software Engineering Dagstuhl Seminar.
Miller, J. A., Baramidze, G., 2005. Simulation and the Semantic Web. In. Proceedings of the 2005 Winter Simulation Conference.
Further Information on this research is at -
Semantic Web - http://www.cems.uwe.ac.uk/amrc/seeds/PeterHale/RDF/RDF.htm.
End-User Programming - http://www.cems.uwe.ac.uk/amrc/seeds/EndUserProgramming.htm.
Modelling - http://www.cems.uwe.ac.uk/amrc/seeds/Modelling.htm.
Semantic Web Modelling - http://www.cems.uwe.ac.uk/amrc/seeds/ModellingSemanticWeb.htm.
The use of Semantic Web languages as information representation and even as programming languages would assist greatly with interoperability as these modelling languages are standardised for use in a wide range of computer systems.
Research can bring together End-User Programming, Modelling and the Semantic Web approaches, so the shaded area is examined.
A methodology that involves structuring of information through Ontology and Semantic Web techniques and enabling end-user programming through visualisation and interaction aims to achieve effective production of generic models. Horrocks (2002) explains Semantic Web technologies and the use of agents and ontologies, and ontology representation languages. This demonstrates the linked nature of Ontology and Semantic Web research.
Berners-Lee and Fischetti (1999) sum up the advantage of a Semantic Web program over programs in other languages. They write, "The advantage of putting the rules in RDF is that in doing so, all the reasoning is exposed, whereas a program is a black box: you don't see what happens inside it." They discuss the use of Semantic Web languages as programming languages and explain the benefits declaring "The Semantic Web, like the Web already, will make many things previously impossible just obvious. Visual Semantic Web programming is one of those obvious things".
Berners-Lee et al. (2006) explain the importance of visualisation for navigation of information "Despite excitement about the Semantic Web, most of the world's data are locked in large data stores and are not published as an open Web of inter-referring resources. As a result, the reuse of information has been limited. Substantial research challenges arise in changing this situation: how to effectively query an unbounded Web of linked information repositories, how to align and map between different data models, and how to visualise and navigate the huge connected graph of information that results." The use of Semantic Web languages as programming languages would assist greatly with interoperability as these languages are standardised for use in a wide range of computer systems
The main advantage of open standard representation of information provided by the Semantic Web is that information can be transferred from one application to another. Additionally it provides a layered architecture that allows for a stepped translation from users to computer and back for conveying results of a modelling run. The program transformation approach argued for by Lieberman (2007) can be used to translate from a domain expert End-User Programmer abstraction to models represented by Semantic Web languages, ontologies and code.
Use of Semantic Web technologies is a means for open standard representation of collaborative models, transformation into different representations as required, and for provision of a high-level interface as a tool for model visualisation and system creation. Structuring of information through Ontology and Semantic Web techniques and enabling End-User Programming through visualisation and interaction can achieve effective production of generic models. Semantic Web technologies could assist greatly with Web based Simulation and Modelling. Kuljis and Paul (2001) evaluate progress in the field of web simulation. They argue the need for web-based simulations to be focussed on solving real-world problems in order to be successful. Miller and Baramidze (2005) establish that for a "simulation study that includes model building, scenario creation, model execution, output analysis and saving/interpreting results. Ontologies can be useful during all of these phases." Model-Driven Programming and the Semantic Web are explained by Frankel et al. (2004).
Research in the use and visualisation of Semantic Web information can provide the tools that end-user programmers have been lacking until recently, and these tools can be used for modelling. Crapo et al. (2002) assert the need for a methodology for creation of systems to enable more collaborative approaches to modelling by domain expert end-users, and that this combined with visualisation would allow engineers to model problems accurately.
Many organisations produce text based reports from their IT systems. But text based reports do not always show information well enough for good decision making. Automated conversion of these reports into Semantic Web languages could assist greatly with this. So a translation process is required and can be implemented as part of an overall User-Driven Modelling/Programming Approach. Once reports are converted to a standardised representation, hierarchical information can be represented as clickable trees and numerical representation as charts. This makes it possible to customise outputs from existing IT systems and so allows an improvement in readability of information without major changes to the way it's produced. This could provide a large gain at little cost.
References
Berners-Lee, T., Fischetti, M., 1999. Weaving the Web. Harper San Francisco; Paperback: ISBN:006251587X
Berners-Lee, T., Hall, W., Hendler, J., Shadbolt, N., Weitzner, D. J., 2006. Creating a Science of the Web. Science 11 August 2006:Vol. 313. no. 5788, pp. 769 - 771.
Crapo, A. W., Waisel, L. B., Wallace, W. A., Willemain, T. R., 2002. Visualization and Modelling for Intelligent Systems. In: C. T. Leondes, ed. Intelligent Systems: Technology and Applications, Volume I Implementation Techniques, 2002 pp 53-85.
Frankel, D., Hayes, P., Kendall, E., McGuinness, D., 2004. The Model Driven Semantic Web. In: 1st International Workshop on the Model-Driven Semantic Web (MDSW2004) Enabling Knowledge Representation and MDA® Technologies to Work Together.
Horrocks, I., 2002. DAML+OIL: a Reason-able Web Ontology Language. In: proceedings of the Eighth Conference on Extending Database Technology (EDBT 2002) March 24-28 2002, Prague.
Kuljis, J., Paul, R. J., 2001. An appraisal of web-based simulation: whither we wander?. Simulation Practice and Theory, 9, pp 37-54.
Lieberman, H., 2007. End-User Software Engineering Position Paper. End-User Software Engineering Dagstuhl Seminar.
Miller, J. A., Baramidze, G., 2005. Simulation and the Semantic Web. In. Proceedings of the 2005 Winter Simulation Conference.
Further Information on this research is at -
Semantic Web - http://www.cems.uwe.ac.uk/amrc/seeds/PeterHale/RDF/RDF.htm.
End-User Programming - http://www.cems.uwe.ac.uk/amrc/seeds/EndUserProgramming.htm.
Modelling - http://www.cems.uwe.ac.uk/amrc/seeds/Modelling.htm.
Semantic Web Modelling - http://www.cems.uwe.ac.uk/amrc/seeds/ModellingSemanticWeb.htm.
Monday, April 21, 2008
Visualising Reports
Many organisations produce text based reports from their IT systems. But text based reports don't always show information well enough for good decision making. Automated conversion of these reports into Semantic Web languages could assist greatly with this. So a translation process is required and can be implemented as part of an overall User Driven Modelling/Programming Approach. Once reports are converted to a standardised representation, hierarchical information can be represented as clickable trees and numerical representation as charts.
This makes it possible to customise outputs from existing IT systems and so allows an improvement in readability of information without major changes to the way it's produced. This could provide a large gain at little cost.
Examples of Visualisations are here - http://www.cems.uwe.ac.uk/amrc/seeds/Visualisation.htm#VisualisationExamples.
Chart/Graph type visualisations are here - http://www.cems.uwe.ac.uk/amrc/seeds/PeterHale/Charts/charts.htm.
Sunday, April 13, 2008
Space Horizons
This project just uploaded uses RSS and design skills of University of the West of England to create a space related educational news site. The RSS news page provides an automated update of space news, and there is also an events page and picture gallery.
Space Horizons - http://www.cems.uwe.ac.uk/amrc/JANS/spacehorizons/ - Space Horizons is a project that aims to deliver ideas on space and any other related information. Based in the South-West of England, Space Horizons also promotes the idea of space tourism which we are very much involved with. It's the place to be for any space related news, events and information in the South West of England! - Information Technology Management for Business - Year 2.

Space Horizons - UWE - JANS Student Group Project
Project Summary
For this project, we will provide a web environment to explain the business and economics of space, enable improved collaboration amongst space companies and OEMs (Original Engineering Manufacturers). This will help promote and develop the UK's space capability. There are growing opportunities for UK space industry in space tourism, moon and mars missions, satellites, and robotic missions. This project will build on the team members' extensive experience in decision support modelling and visualisation, especially within the aerospace industry. Our strategy is to make available the kind of systems we developed for aerospace companies' internal decision support systems to all industry, organisations and the public. Our partners for this are the West of England Aerospace Forum (WEAF) http://www.weaf.co.uk/ who will be allowing us to extract, visualise and extend the interactivity of their aerospace company network information. We will build an environment where individuals and companies can create their own models. The initial focus is on the space domain, though the techniques will be applicable to any domain. We will enable a wide range of people to create models as well as linking to and visualising server based models. The means to achieve this is provision of freely available, web-based, visual model creation tools that require the minimum possible code writing expertise from end-users. For the complex, interdependent space sector, simplicity of communication and access is essential.
The primary aim for this feasibility study is to establish a method to represent complex models and information in a way that is interactive, accessible and understandable by a wide range of users. This will enable space (and aerospace) industries in the SW region to access relevant information rapidly, and ensure efficient economic interactions throughout the supply chain. The focus for this system will be on using ICT to achieve a long-term aim of providing cheaper and more efficient space transport and so aid the development of this sector of the UK aerospace industry. This will be enabled by the capture and distribution of engineering knowledge for the space transport sector in a novel, and constructionist, 'e-science' environment. There are two main strands to this research:
- modelling of the economics of the space industry using web based technology
- enabling organisations and the non-specialist to model problems, by creating a system that employs end-user programming.
A further objective will be to establish a forum for involvement of aerospace companies, organisations, and the public in furthering collaborative space expertise and investment. The space industry will be used as a test vehicle, though it is clear that this approach could be employed in many areas, including industrial, educational, scientific and business sectors. This feasibility study will enable validation of our approach prior to the application of modelling techniques to these other sectors.
The digital technologies used and the subject area of the space industry are economic opposites. Web software especially is a market where comparatively little acquisition investment is required. Space at present requires massive investment so there is a tendency towards monopoly/oligopoly. Though economic theory tells us that monopoly leads to abnormal profits, this is only sometimes the case with space efforts, this depends on the engineering and scientific difficulty, production techniques and the project aims scientific/commercial. Where the aims are mainly scientific, public money is usually required, through government led agencies, though suppliers may make profits. Simpler and clearer modelling would help to reduce space investment and operational costs. User driven programming assists in increasing the value of workers in relation to ICT, an aim of the World Bank Working Paper (Zhen-Wei Qiang et al., 2004). Thus, it addresses two areas of skill shortage, which are hampering the UK economy, and slowing growth.
Zhen-Wei Qiang C, Pitt A, Ayers S, 2004. Zhen-Wei Qiang C, Pitt A, Ayers S, 2004, Contribution of Information and Communication Technologies to Growth.
Friday, April 04, 2008
Who will write tomorrow's code?
This article on the BBC Technology Website by Bill Thompson illustrates aspects of the history of programming and examines the availability of future programmers.
This is at - http://news.bbc.co.uk/1/hi/technology/7324556.stm.
"Bill Thompson describes the history of "personal computers like the IBM PC, home systems like the Spectrum and of course to the BBC Microcomputer," - "characterised by programmability, by the ability of users to write their own code".
"Just like EDSAC the BBC Micro was open to developers to work on, coming with the BASIC programming language and even a schematic showing the circuitry inside for those more interested in hardware than software."
"Along with the Spectrum and even the ZX81 it was a computer that encouraged those using it to learn to program for themselves."
"The BBC offered support with television programs, magazines with long BASIC programs to be typed in and improved upon were published, and there was a sense that understanding computers meant being able to do more than just run applications.
"Today, with over two billion PCs, three billion mobile phones and well over a billion internet users the ways in which information and communications technologies shape the modern world are obvious."
"The revolution succeeded, and we now live in the wired world of digital data, fast networks and computerised systems."
Bill Thompson argues "we need good programmers for the UK's software industry and at the moment we do not have enough of them."
Since the eighties and computers like the BBC Micro the emphasis on programming computers has reduced and use of applications is the main aim of most people. Although with Web 2.0 there is more User Generated Content created there are still limits to the customisation and development of applications by end-users. If the ease of use/programming of early BBC micros was brought to current applications and an easier transition from using to programming, this would be a powerful end-user programming environment. Then greater numbers of computer literate users would take on programming.
More information from my website on these subjects is available at - http://www.cems.uwe.ac.uk/amrc/seeds/EndUserProgramming.htm and http://www.cems.uwe.ac.uk/amrc/seeds/PeterHale/EndUserHistory.htm.
This is at - http://news.bbc.co.uk/1/hi/technology/7324556.stm.
"Bill Thompson describes the history of "personal computers like the IBM PC, home systems like the Spectrum and of course to the BBC Microcomputer," - "characterised by programmability, by the ability of users to write their own code".
"Just like EDSAC the BBC Micro was open to developers to work on, coming with the BASIC programming language and even a schematic showing the circuitry inside for those more interested in hardware than software."
"Along with the Spectrum and even the ZX81 it was a computer that encouraged those using it to learn to program for themselves."
"The BBC offered support with television programs, magazines with long BASIC programs to be typed in and improved upon were published, and there was a sense that understanding computers meant being able to do more than just run applications.
"Today, with over two billion PCs, three billion mobile phones and well over a billion internet users the ways in which information and communications technologies shape the modern world are obvious."
"The revolution succeeded, and we now live in the wired world of digital data, fast networks and computerised systems."
Bill Thompson argues "we need good programmers for the UK's software industry and at the moment we do not have enough of them."
Since the eighties and computers like the BBC Micro the emphasis on programming computers has reduced and use of applications is the main aim of most people. Although with Web 2.0 there is more User Generated Content created there are still limits to the customisation and development of applications by end-users. If the ease of use/programming of early BBC micros was brought to current applications and an easier transition from using to programming, this would be a powerful end-user programming environment. Then greater numbers of computer literate users would take on programming.
More information from my website on these subjects is available at - http://www.cems.uwe.ac.uk/amrc/seeds/EndUserProgramming.htm and http://www.cems.uwe.ac.uk/amrc/seeds/PeterHale/EndUserHistory.htm.
Sunday, March 23, 2008
PhD Findings and Conclusion
Findings
The thesis covered the following areas :-
- Enabling people to create software visually.
- Creating design abstractions familiar to domain experts e.g. diagrams for engineers.
- Ensuring interoperability using open standards.
- Automating user to computer translation process.
This post explains how the alternative approach of User Driven Modelling/Programming used for this thesis to develop models and modelling capabilities compared to that of spreadsheet development, used within other projects. The alternative approach was outlined in this thesis, of using open standards ontologies/taxonomies and a web interface for developing decision support models for design and costing. The stepped translation approach designed and implemented in this thesis enabled structured modelling, and visualisation using interactive technologies.
- Step 1 - Ontology
- Step 2 - Modelling Tool
- Step 3 - Interactive Visualisation
This stepped translation solved problems of the spreadsheet approach as indicated in the table below, and then in more detail in following sections -
Improvement - Achieved By
Maintenance - Structuring and Translation
Extensibility - Structuring and Visualisation
Ease of Use - Visualisation, Interaction, and Translation
Sharing of Information - Shared Ontology and Interoperability
The 3 step translation process created ensures translation of domain level modelling into open standard representation and software and vice versa.
Maintenance
The use of a centralised information source makes these models more reliable than the standalone spreadsheet. This centralised structure was easier to manage than updating multiple instances of the spreadsheets used by different people and ensuring they all contain the same information. So the first task was to build a system for collaborative model building. As a piece of information can then only belong to a unique location, the problems arising from duplicate pieces of information are eliminated. The models have only the functionality that is added by the model builder so there are not other side effects to keep track of, as there are with generic functionality within spreadsheets. Enabling people to create software visually makes it easier for model builders and model users to keep track of any information they are responsible for. Translation from the ontology to models and visualisations ensures one change will affect all stages, so this makes maintenance easier.
Extensibility
Creating the infrastructure for the collaborative model building system took much more time than it did for the spreadsheet system, but having done so it is quicker and easier to create further models. This is because of the facilities provided for model builders and end-users to customise the software in any one of the three step translation process. This means progress has been made in making it possible for non-programmers to build models. It also indicates that the extra research and development time taken was worth it in the long term, most of this time involved productive research and this can be used in future projects. The use of open standards in this thesis for information and models ensures there should be a development path, whatever changes there may be in the software market. This use of open standards also ensures that the system can link with most environments used by others. The translation and visualisation approach ensures that new models can be added using the existing ontology, and that design changes in the ontology and translation can enable modelling of different problems. So if there is a new problem to be modelled there are two ways to achieve this.
Ease of Use
Many people now are familiar with web pages and at least the basics of how to navigate them, and by creating such an environment, and standardising the navigation to those ways commonly used over the web, it is possible to ease usability. The models contain only the functionality that is added by the model builder unlike the spreadsheets which had generic functionality that was not required and led to user’s confusion. New Web 2.0 interaction technologies have allowed production of a rich user interface for web programs in a similar way to single computer applications. This means information held in an ontology and translated through modelling tools can be made available as interactive applications for many users. Translation allowed the same user interface to be provided in multiple tools and computer languages. Also this research showed that it was possible to provide user interfaces and visualisation differently as appropriate according to the type of user, the situation, or the kind of information to be shown.
Sharing of Information
The use of open standards languages for representing information makes it much easier to represent information in a way that makes it accessible both to people and software. Ontology based modelling tools use these open standards and so ensure dependable translation, interoperability, and sharing of information. Web browsers make it possible to share information with many users at once, and so this enables collaboration. Structuring of the information using standardised languages makes it easier to search and visualise the information. This ensuring of interoperability is important for long term use of the overall modelling system.
Conclusion
Within this thesis it is argued that there is a need for software developers to create programs that enable users to solve problems themselves. In effect this involves production of a system to create systems. This approach can widen programming participation by including computer literate non-programmers. This is a reaction to the increased complexity of real world problems and software systems, which makes development of software solutions impractical without greater involvement from end-users. It is difficult for developers to foresee every need of users and use of the software produced, so it makes sense to enable more end-user customisation. It is also argued that the research for this thesis has been a step towards making end-user programming possible. The research ideas look complex at first glance but this research is all about simplifying software development.
The approach of developing decision support models for design and costing using a spreadsheet was compared to the alternative approach of using open standards taxonomies and a web interface for this purpose. The conclusion is that although use of spreadsheets allows for the creation of models relatively quickly they are beset by problems. These relate to Maintenance, Extensibility, Ease of Use, and Sharing of Information. The spreadsheet example and the explanation in the thesis represent problems currently experienced throughout software and computer use.
The alternative approach for this thesis of User Driven Modelling/Programming involves the development of a system, where a model builder, via visual editing of library taxonomies can undertake maintenance and extension of information. Dealing with this proof of concept has indicated that it is easier to maintain, search and share information using this approach than it was using spreadsheets. This also enables much more of the maintenance task to be left to users, who can also customise the system. Creating the infrastructure has taken much more time than it did for the spreadsheet system, but having done so it is much quicker and easier to create further models. This indicates that the extra research and development time taken though far exceeding what would have been required for a spreadsheet modelling project is well worth it in the long term. Also the use of a centralised information source makes these models more reliable than the standalone spreadsheet, standalone decision support models created individually may contain out of date information. In addition, since a well constructed ontology implies that a piece of information can only belong to a unique location, the problems arising from duplicate pieces of information are eliminated. It is also much easier to create models once the infrastructure is in place; this can enable users to develop models. The ability to visualise, search and share information using structured languages and web pages is a huge advantage for creation of dynamic structured views and decision support models over the web.
This research was a test case for a whole new approach that could be possible, of collaborative end-user programming by domain experts. The end-user programmers can use a visual interface where the visualisation of the software exactly matches the structure of the software itself, making translation between user and computer, and vice versa, much more practical. For this reason highly structured visualisations were preferred over web spreadsheets. Semantic Web languages are ideal for representing graphs and trees in an open standard way. The spatial, and tree/graph visualisations used both have the same underlying semantics, and therefore can both be translated to computer languages. In fact it would be much better in the long run to use the Semantic Web languages as standardised programming languages for such problems as this would avoid the need to further translate into other programming languages, and systems. The advantage to this is that of using Semantic Web languages for representation of information, meta-programming, and translation to a visual display for users. The use of Semantic Web languages as a connectivity environment for connecting information, and for connecting users to the information held in Semantic Web data sources enables an environment that could be made easier to use, install and maintain.
More generally a new approach is required to software creation. This approach should involve developers creating software systems that enable users to perform high level programming, and model the problem for which they are the experts. This is an alternative to the provision by developers of modelling solutions that try to provide an out of the box solution that just needs ’tweaking’. Such an out of the box system is not practical considering both increases in complexity of manufactured products, and of software systems themselves. Feedback from publishing the research examples behind this thesis and working with industrial partners indicates that people like to work on their own solutions, providing they are computer literate and confident they have domain knowledge that the developers do not possess. This is true for software development in general, not just in the domain of engineering. Research cited in this thesis from others involved in end-user programming confirms this.
For proving the hypothesis that it is possible to create an end-user programming environment, usable by non programmers, it has been found that structuring and relating of information is all important in this solution. To achieve this, it was only necessary to link the information visually via equations, and store these results for reuse and collaboration. If users can understand and navigate relationships, and add new relationships they can model most problems. It was important to design a visual interface that is intuitive to use, and allows for proper interpretation of the results. Feedback has indicated that users can navigate this structure and manipulate it. This is preferable to ’black box’ solutions that hide information. There are no dead ends or blocks to expanding and improving this approach. To make the system easier to use it is only necessary to trial continually better interfaces, and to assist by providing guidance to the user. There was not sufficient time and resources to expand this research much to areas outside engineering modelling, but there is scope for researchers to improve end-user programming for engineering modelling systems, and to expand the research into other areas.
Friday, March 14, 2008
The SVG (Scalable Vector Graphics Conference) is on this August.
SVG Open 2008 - http://svgopen.org/2008/index.php - 6th International Conference on Scalable Vector Graphics - 26th to 28th August - Nuremberg - Germany - The world conference on SVG will this year take place in the center of Nuremberg. Located in the south of Germany.
I have an SVG page at - http://www.cems.uwe.ac.uk/amrc/seeds/PeterHale/SVG/SVG.htm - with more information.
Saturday, March 01, 2008
PhD Thesis Summary
There are many computer literate people who are experts in a particular domain. This research examines enabling computer literate engineers to model problems in software by minimising the code writing they need to undertake. Software development is difficult for many engineers as they often do not have the time, experience, or access to software development tools necessary to model their problems. Using a combination of modelling via use of formulae (equations) and visualisation of the way these formulae interact it is possible to construct modelling software without requiring code. Crapo et al (2002) explain the need for a methodology for creation of systems to enable more collaborative approaches to modelling by domain expert end-users, and that this combined with visualisation would allow engineers to model problems accurately. This technique of User Driven Modelling/Programming could be widely applicable to any problem that requires linked equations to be represented and tracked, and results from these calculated. While some argue that end-user programming is an insurmountable problem, this problem could be tackled by many researchers co-operating to create specific solutions to different kinds of end user programming problems while also sharing findings, to assist with progress towards a more generic solution.
Crapo, A. W., Waisel, L. B., Wallace, W. A., Willemain, T. R., 2002. Visualization and Modelling for Intelligent Systems. In: C. T. Leondes, ed. Intelligent Systems: Technology and Applications, Volume I Implementation Techniques, 2002 pp 53-85.
More Information is available on my Home Page at - http://www.cems.uwe.ac.uk/~phale/.
Subscribe to:
Posts (Atom)