This is the paper and presentation I gave for Postgraduate Conference for Computing: Applications and Theory (PCCAT 2011) - June 8th 2011 - http://www.pccat.ex.ac.uk/index.php?pid=1
The paper is titled - Requirements and software engineering for tree-based visualisation and modelling: A user driven approach
This is the link where I placed it in the University of the West of England Research Repository. The PowerPoint presentation I gave is also there. There are Word and PowerPoint 2007 files and also PDF versions. These are all available from this link - https://eprints.uwe.ac.uk/15077/.
This is the abstract -
Abstract
This paper is about potential to provide an interactive visual ontology/taxonomy based modelling system. The research is part of efforts to structure, manage, and enable understanding of complex engineering, business and/or scientific information to enable those involved to collaborate using a systems approach. The aim and objectives are to provide a taxonomy management system to close the link between requirements gathering and end-user modellers. The research is into modelling of product data structures. This research could be adapted to business process modelling, and biology taxonomy visualisation/representation. The modelling system was developed to assist decision support for problems such as wing and engine design. The methodology involves modelling using tree structured ontology based modelling. It is argued that visualising this structure enables improved Maintenance, Extensibility, Ease of Use, and Sharing of Information, and so enables better and more accessible modelling. This is achieved by uniting the software taxonomy structure with the structure of the domain to be modelled and visualised, and using Semantic Web technologies to link this with ontologies and to end-users for visualisation. This research assists with management of development, use, and re-use of software in order to make this an integrated process. The research brings together related fields of Semantic Web, End-User Programming, and Modelling, to assist domain expert end users.
Further information -
I've published my more general thoughts about the benefits of Postgraduate Conferences and Research Repositories to students, in the UK Vitae (organisation for research students and staff) - What's Up Doc Blog - http://www.vitae.ac.uk/researchers/346441/Whats-up-doc-blog-for-postgraduate-researchers.html. I publish my thoughts that are more general to all researchers rather than my specific research to there -this is my post to that blog - http://www.vitae.ac.uk/researchers/346441-406701/Getting-your-Research-Published---PostGraduate-Conferences.html.
Showing posts with label Visualisation. Show all posts
Showing posts with label Visualisation. Show all posts
Thursday, June 23, 2011
Saturday, March 19, 2011
Postgraduate Conference for Computing: Applications and Theory (PCCAT 2011)
I have submitted a paper to this conference at Exeter University in June. These are the details of the conference - http://www.pccat.ex.ac.uk/ -
"Home Page
Welcome to the website of the second Postgraduate Conference for Computing: Applications and Theory (PCCAT 2011). Following the great success of PCCAT 2010, we are pleased to announce that the University of Exeter will host PCCAT on 8th June 2011.
PCCAT 2010 proved a great success, both in terms of networking and introducing the vital world of conferencing to postgraduate students.
We are inviting the submission of abstracts, which if accepted will be extended into either a short paper or a poster for presentation on the day. More details can be found on the Submissions Page
In the new year, we will be inviting interested parties to join the paper review panel, which will be responsible for reviewing and providing feedback for short papers. If this is something you feel you would be interested in, please contact us (details of how to contact the committee are here
We hope to see you at PCCAT 2011, and look forward to hearing from you.
Max Dupenois and David Walker
(PCCAT 2011 Programme Chairs)"
This is my Abstract for the paper -
"Abstract: This paper is about potential to provide an interactive visual taxonomy management system. It has been and is part of efforts to structure, manage, and enable understanding of complex engineering, business and/or scientific information to enable those involved to collaborate using a systems approach. The aim and objectives are to close the link between requirements gathering and end-user modellers. The main subject will be editing and display of product data structures (already implemented), business process modelling, and discussion of possible application to phylogenic/phylogenetic (biology taxonomy) knowledge. Modelling in all these areas could make possible new insights. This approach could also be used for public understanding work and visualisation, e-science, and information management. The aim is to apply novel end-user programming research to enable the editing, management, and representation of anything tree/taxonomy based by uniting the software taxonomy structure with the taxonomy structure of the domain to be modelled and visualised, and using Semantic Web technologies to link this with overall ontologies then to end-users for visualisation.
The purpose of this work is to ease management of development use, and re-use of software and make this a continuous integrated process.
To achieve the above aim what is necessary is to establish or link to a computing infrastructure for representation of complex, engineering, business, and scientific information. This kind of Computer Science/Software Engineering research allows for bringing together related fields of Semantic Web and ontology/taxonomy management, end-user programming, and visualisation and interaction with complex information. Then management of software development with and for such professionals can be eased and all be involved via the web.
Further, the structure and accessibility of Semantic Web technologies may also assist with broadening this approach to accessibility for people with various disabilities, and also for environmental modelling."
"Home Page
Welcome to the website of the second Postgraduate Conference for Computing: Applications and Theory (PCCAT 2011). Following the great success of PCCAT 2010, we are pleased to announce that the University of Exeter will host PCCAT on 8th June 2011.
PCCAT 2010 proved a great success, both in terms of networking and introducing the vital world of conferencing to postgraduate students.
We are inviting the submission of abstracts, which if accepted will be extended into either a short paper or a poster for presentation on the day. More details can be found on the Submissions Page
In the new year, we will be inviting interested parties to join the paper review panel, which will be responsible for reviewing and providing feedback for short papers. If this is something you feel you would be interested in, please contact us (details of how to contact the committee are here
We hope to see you at PCCAT 2011, and look forward to hearing from you.
Max Dupenois and David Walker
(PCCAT 2011 Programme Chairs)"
This is my Abstract for the paper -
"Abstract: This paper is about potential to provide an interactive visual taxonomy management system. It has been and is part of efforts to structure, manage, and enable understanding of complex engineering, business and/or scientific information to enable those involved to collaborate using a systems approach. The aim and objectives are to close the link between requirements gathering and end-user modellers. The main subject will be editing and display of product data structures (already implemented), business process modelling, and discussion of possible application to phylogenic/phylogenetic (biology taxonomy) knowledge. Modelling in all these areas could make possible new insights. This approach could also be used for public understanding work and visualisation, e-science, and information management. The aim is to apply novel end-user programming research to enable the editing, management, and representation of anything tree/taxonomy based by uniting the software taxonomy structure with the taxonomy structure of the domain to be modelled and visualised, and using Semantic Web technologies to link this with overall ontologies then to end-users for visualisation.
The purpose of this work is to ease management of development use, and re-use of software and make this a continuous integrated process.
To achieve the above aim what is necessary is to establish or link to a computing infrastructure for representation of complex, engineering, business, and scientific information. This kind of Computer Science/Software Engineering research allows for bringing together related fields of Semantic Web and ontology/taxonomy management, end-user programming, and visualisation and interaction with complex information. Then management of software development with and for such professionals can be eased and all be involved via the web.
Further, the structure and accessibility of Semantic Web technologies may also assist with broadening this approach to accessibility for people with various disabilities, and also for environmental modelling."
Wednesday, December 08, 2010
Open Standard Layered Architecture for computer to human translation
This diagram shows a central infrastructure of an open standards layered architecture. This enables interoperability at the Computer to computer layer. This gives advantages to developers for maintenance and re-use. This infrastructure aids translation from computer and developers upwards, to end users. Visualising the model/program structure translated upward from code to a navigable interactive visualisation enables accessibility, thus assisting with modelling and end user programming. This infrastructure that aids computer to computer interoperability thus also aids human to human collaboration. This all aids ease of use and re-use of models/programs also.
So far this translation has been enabled upwards from computer to human. Future research could involve translation from human to computer and interaction to make this an iterative, interactive life-cycle process. 
So far this translation has been enabled upwards from computer to human. Future research could involve translation from human to computer and interaction to make this an iterative, interactive life-cycle process.

Wednesday, November 24, 2010
Abstract and Poster - BBSRC (Biotechnology and Biological Sciences Research Council) AHRC (Arts & Humanities Research Council) Workshop
BBSRC (Biotechnology and Biological Sciences Research Council) AHRC (Arts & Humanities Research Council) Workshop - 16th and 17th November 2010 - Abstract and Poster - Requirements for Phylogenetic Tree Visualisation - A User Driven Approach - Authors: Peter Hale, Tony Solomonides, Ian Beeson, Neil Willey, Karen Bultitude, Darren Reynolds
Abstract: This poster presentation is about potential to provide an interactive visual taxonomy management system. It will be part of our efforts to structure, manage, and enable understanding of complex scientific information to enable scientists to collaborate using a systems approach. The main subject will be editing and display of phylogenic/phylogenetic knowledge, this could make possible new insights. The project will build on the knowledge of the Faculty of Health and Life Sciences (FHLS) in this biological field, the FHLS Science Communication Unit’s excellent public understanding work and the visualisation, e-science, and information management abilities of the Centre for Complex Cooperative Systems (CCCS) The CCCS team will apply novel end-user programming research to enable the editing, management and representation of biological and environmental information including phylogenetic trees.
UWE has established a computing infrastructure for representation of complex scientific information, has in depth experience in applied scientific research, and on public understanding of science outreach. UWE Computer Science research allows for bringing together related fields of Semantic Web and ontology/taxonomy management, end-user programming, and visualisation and interaction with complex information.
Although web based taxonomies already exist, there are still opportunities to improve the visualisation and interactivity capabilities of taxonomy representation. In addition, Semantic Web techniques can enable automated structuring and management of information.
This research in management, structuring, and visualisation of information will enable visualisation of complex e-science problems to assist in enabling understanding of them, and the CCCS centre has many years of experience in gathering and enabling representations of such problems. This will enable the UWE Science Communication Unit to manage a process of making information managed in this project public. The main scientific information will be based on the work of experienced Faculty of Applied Science (FAS) researchers in Biology and Environmental Sciences. These staff have many years of research experience and much research data to make publicly available, such as phylogenetic information. The taxonomy management system will enable the use of such information and a methodology for its representation and contextualisation in varied interactive ways, according to what is most useful for particular people and types of information. This could be applied to the field of phylogenetic systematic in order to combine biological and environmental approaches and solutions.
UWE has used this technology and approach to visualise engineering product data structures and processes, but there is no reason why this strategy could not be applied to visualisation of phylogenetic taxonomy structures and to the debate on how to classify life forms which is an ontology matter. The use of visualisation via end-user HCI advances and the Semantic Web can widen this debate.
Poster - https://docs.google.com/viewer?a=v&pid=explorer&chrome=true&srcid=0Bx_KguSfl6vSZDM2ZGY3ZjMtOTNlZi00YmJjLWI2MWItODJjNWRmYmVmNzNh&hl=en.
Abstract: This poster presentation is about potential to provide an interactive visual taxonomy management system. It will be part of our efforts to structure, manage, and enable understanding of complex scientific information to enable scientists to collaborate using a systems approach. The main subject will be editing and display of phylogenic/phylogenetic knowledge, this could make possible new insights. The project will build on the knowledge of the Faculty of Health and Life Sciences (FHLS) in this biological field, the FHLS Science Communication Unit’s excellent public understanding work and the visualisation, e-science, and information management abilities of the Centre for Complex Cooperative Systems (CCCS) The CCCS team will apply novel end-user programming research to enable the editing, management and representation of biological and environmental information including phylogenetic trees.
UWE has established a computing infrastructure for representation of complex scientific information, has in depth experience in applied scientific research, and on public understanding of science outreach. UWE Computer Science research allows for bringing together related fields of Semantic Web and ontology/taxonomy management, end-user programming, and visualisation and interaction with complex information.
Although web based taxonomies already exist, there are still opportunities to improve the visualisation and interactivity capabilities of taxonomy representation. In addition, Semantic Web techniques can enable automated structuring and management of information.
This research in management, structuring, and visualisation of information will enable visualisation of complex e-science problems to assist in enabling understanding of them, and the CCCS centre has many years of experience in gathering and enabling representations of such problems. This will enable the UWE Science Communication Unit to manage a process of making information managed in this project public. The main scientific information will be based on the work of experienced Faculty of Applied Science (FAS) researchers in Biology and Environmental Sciences. These staff have many years of research experience and much research data to make publicly available, such as phylogenetic information. The taxonomy management system will enable the use of such information and a methodology for its representation and contextualisation in varied interactive ways, according to what is most useful for particular people and types of information. This could be applied to the field of phylogenetic systematic in order to combine biological and environmental approaches and solutions.
UWE has used this technology and approach to visualise engineering product data structures and processes, but there is no reason why this strategy could not be applied to visualisation of phylogenetic taxonomy structures and to the debate on how to classify life forms which is an ontology matter. The use of visualisation via end-user HCI advances and the Semantic Web can widen this debate.
Poster - https://docs.google.com/viewer?a=v&pid=explorer&chrome=true&srcid=0Bx_KguSfl6vSZDM2ZGY3ZjMtOTNlZi00YmJjLWI2MWItODJjNWRmYmVmNzNh&hl=en.
Wednesday, July 07, 2010
Ways of providing openness in a web age
What interests me is the implications of this report on the need for and ways of providing research information. A change is necessary in order to find ways to involve and inform people in an age of blogs, Wikis, and Web 2.0/3.0 and Semantic Web.
Further it is important then to be able to visualise complex data and uncertainty in combination with text, so that it is understandable and conveys the true meaning. This is a problem that in itself needs research.
CRU climate scientists 'did not withold data' - http://news.bbc.co.uk/1/hi/science_and_environment/10538198.stm
By Richard Black
Environment correspondent, BBC News
Climate e-mails review condemns lack of openness - http://www.bbc.co.uk/blogs/opensecrets/2010/07/climate_emails_review_condemns.html
Martin Rosenbaum
Further it is important then to be able to visualise complex data and uncertainty in combination with text, so that it is understandable and conveys the true meaning. This is a problem that in itself needs research.
CRU climate scientists 'did not withold data' - http://news.bbc.co.uk/1/hi/science_and_environment/10538198.stm
By Richard Black
Environment correspondent, BBC News
Climate e-mails review condemns lack of openness - http://www.bbc.co.uk/blogs/opensecrets/2010/07/climate_emails_review_condemns.html
Martin Rosenbaum
Saturday, April 10, 2010
Empowering engineers and others to create software
With my PhD work, there was extensive prototyping of software solutions created and feedback from engineers. At first engineers tended to ask for software that followed the strategy of the business and met its deadlines. What emerged over time though was a desire from engineers to have more control over the software so that they could do this themselves and have input into this strategy. With a top down strategy and inflexible software and rules about what can be used and installed, missing of deadlines, and problems in meeting aims were built into the system, and engineers realised this.
So even in engineering, an industry that by its nature has to be conservative, due to safety needs, it is realised that empowerment is necessary in software development. So there was a need to empower the engineers by provision of collaborative software that could be installed and used as easily as possible and be adaptable. Empowering the engineers to be fully involved in the creation and maintenance of such software, because they're interested in the software and what it can do, was essential to make the use, re-use and maintenance of the software practical. This is necessary because it would not be possible to achieve application of useful software by any top down strategy, with limited involvement of higher managers and software suppliers. Visualisation and modelling of the software by a large range of people can be achieved by use of diagrams to show the problem and software structure, as part of the software and how it is used.
Further feedback was obtained from others via an online survey of a greater cross section of others rather than only engineers. This bore out that people want more control and involvement in software development and use, and that visual editing of the software over the web is the best way to achieve this.
So even in engineering, an industry that by its nature has to be conservative, due to safety needs, it is realised that empowerment is necessary in software development. So there was a need to empower the engineers by provision of collaborative software that could be installed and used as easily as possible and be adaptable. Empowering the engineers to be fully involved in the creation and maintenance of such software, because they're interested in the software and what it can do, was essential to make the use, re-use and maintenance of the software practical. This is necessary because it would not be possible to achieve application of useful software by any top down strategy, with limited involvement of higher managers and software suppliers. Visualisation and modelling of the software by a large range of people can be achieved by use of diagrams to show the problem and software structure, as part of the software and how it is used.
Further feedback was obtained from others via an online survey of a greater cross section of others rather than only engineers. This bore out that people want more control and involvement in software development and use, and that visual editing of the software over the web is the best way to achieve this.
Friday, April 02, 2010
Unified Computing For Engineering, Business and Science
The research undertaken and described here crosses the boundary between engineering and computing. This is achieved by reusing the same approach for computer modelling and engineering modelling, thus applying computing use case and tree based node and object design. This approach is usable for any kind of tree and network based modelling e.g. engineering process modelling, workflow, business process modelling. The approach makes use of nodes linked by equations, or pure taxonomies if equations aren't required, thus making this useful for taxonomies, and useful for representing computing structures, biology, and engineering structure. When these taxonomies are linked up, they can then be used for a colour coded visualised ontology super taxonomy, of sub taxonomies e.g. processes, materials, components (engineering or computer software), resources, and cost rates.
The visualisation represents the structure of the model, and the structure of the problem, creating a unified approach for systematic program and model, computing and engineering, business, and biology structure representation. This makes structured representation much clearer than it can be in a flat structure such as a spreadsheet, and makes auditing and keeping track of changes easier.
This unified approach then enables representation of the problem at a high level of abstraction and if the optional equations are included aids process modelling and decision support. This high level of abstraction and structured representation and visualisation makes errors more obvious and findable, aiding auditing. Semantic Web and Web 2.0/3.0 technologies make this approach feasible for moving this approach from more complex to simple low end computing and networking the approach where useful or necessary.
The visualisation represents the structure of the model, and the structure of the problem, creating a unified approach for systematic program and model, computing and engineering, business, and biology structure representation. This makes structured representation much clearer than it can be in a flat structure such as a spreadsheet, and makes auditing and keeping track of changes easier.
This unified approach then enables representation of the problem at a high level of abstraction and if the optional equations are included aids process modelling and decision support. This high level of abstraction and structured representation and visualisation makes errors more obvious and findable, aiding auditing. Semantic Web and Web 2.0/3.0 technologies make this approach feasible for moving this approach from more complex to simple low end computing and networking the approach where useful or necessary.
Friday, January 08, 2010
User driven modelling: Visualisation and systematic interaction for end user programming - SiftMedia
SiftMedia have published online this article of mine.
Article for Knowledge Board - SiftMedia - User driven modelling: Visualisation and systematic interaction for end user programming - http://www.knowledgeboard.com/item/3053/23/5/3.
04-Jan-10
Peter Hale explores to what extent it is possible to improve user-driven collaborative software development through interaction with diagrams and without requiring people to learn computer languages.
Article for Knowledge Board - SiftMedia - User driven modelling: Visualisation and systematic interaction for end user programming - http://www.knowledgeboard.com/item/3053/23/5/3.
04-Jan-10
Peter Hale explores to what extent it is possible to improve user-driven collaborative software development through interaction with diagrams and without requiring people to learn computer languages.
Wednesday, June 24, 2009
Collaborative Modelling and Visualisation For Complex Systems
The aim of the research described in this article is to apply the research first where it can have the most use,and then encourage others to expand it for other domains and other users. This is in order to simplify modelling and computing for computer literate non programmers, this includes many engineers, and so enable users such as engineers to model the manufacturing and design.
The problem to be tested her is enabling de-abstraction of engineering problems from engineers' representation to computer models and code. This is order to find out to what extent diagrammatic representations of problems can be used in order to provide modelling solutions. So to test this a source tree is created, then translated to computer code, then represented as a result tree.
To test this problem - the research examines a part of C.S. Peirce's (1906) - 'Prolegomena to an Apology for Pragmaticism' call to action"Come on, my Reader, and let us construct a diagram to illustrate the general course of thought; I mean a system of diagrammatization by means of which any course of thought can be represented with exactitude".
It isn't possible to solve this problem and do this all at once so to limit the scope this research is restricted mainly to engineers (who often use diagrams). Engineers often model problems using computer systems, so to make this research effective these areas are prioritised -
- To domain of modelling (which often requires diagrams)
- Management of ontologies and related models is essential for management and understanding of complex systems.
Breaking both the research and the modelling system into testable steps improves the chances of project success. Breaking a complex systems engineering problem or project into modular steps and stages ensures that if failure looks likely it is possible to go back a step, rather than restart or abandon the project. This also informs, teaches and enables systems thinking and design. This can be achieved by transforming engineering knowledge into code in collaborative computer systems, and visualising the structure of the resultant system to all domain experts. This enables translation (both in human communication and computing model and program transformation) from the business and/or engineering focus of the domain expert end-users, to the software developers and help desk and vice versa.
Enabling, providing and supporting staff to use Semantic Web and Web 2.0 technologies can lower costs, improve collaboration, and improve staff satisfaction and retention. This is an important technology for Semantic Web collaboration. Visualisation of every stage in collaborative model creation and every part of the model enables determination of whether the model and view(s) of it are useful and correct, and so aids this sharing of human knowledge to solve problems.
A problem can be represented and shared as visual diagrams, and then translated from this abstract view to models and code. Gross (2007) argues the need for end user programming by designers using diagrams and scratchpads. Tufte (1990) explains how diagrams can be more effective than words for representing geometry. This links with the theme through our research of translating from an abstract to a concrete representation; Green et al. (2007) explain this distinction between abstract and concrete models. This distinction is more gradual than the distinction between classes and objects for object oriented programming. To achieve this it is necessary to enable translation from ontologies and Semantic Web information to diagrammatic representations and vice versa. Green et al. (2007) discuss terminology problems, and how ontologies and models and collaboration can be used to help solve this problem. A classification scheme or ontology is necessary in order to make communication precise. Ontology/ies can be used to define terms and higher level relationships and these extended for application to particular modes. Such ontology/ies can also be used to help non-specialists understand the terminology of a particular domain.
Sternemann and Zelm (1999) explain that it has become necessary to research collaborative modelling and visualisation tools, because of the business trend towards global markets and decentralised organisation structures; Green et al. (2007) also explain this.
The benefits of this research are - enabling engineers to visualise problems such as representation of a product data structure in a familiar way. This gives a visual and colour coded representation of equations. Visualisation is easier to navigate and understand than that in spreadsheets, and more maintainable. The translation, visualisation and interactions close the gap between human representations of problems, and the representations that are possible using computer languages.
The Wider Implications of this research is that this research could also be used for business modelling, process modelling, and workflow.
References
Green, S., Beeson, I., Kamm, R., 2007. Process architectures and process models: opportunities for reuse. In: 8th Workshop on Business Process Modeling, Development, and Support BPMDS07 and CAiSE'07 11-15 June 2007, Trondheim, Norway.
Gross, M. D., 2007. Designers Need End-User Software Engineering. In: End-User Software Engineering Dagstuhl Seminar February 2007.
Peirce, C.S. - 1906. Prolegomena to an Apology for Pragmaticism - http://www.existentialgraphs.com/peirceoneg/prolegomena.htm.
Sternemann, K. H., Zelm, M., 1999. Context sensitive provision and visualisation of enterprise information with a hypermedia based system, Computers in Industry Vol 40 (2) pp 173-184.
Tufte, E., R., 1990. Envisioning Information. Graphics Press.
Wednesday, June 03, 2009
Decision Support Tool Representation
It's important to close the gap between ontology representation and modelling and visualisation of problems. There is much more incentive to poulate an ontology or database if the information in this is automatically or semi automatically translated for use in modelling and decision support. Then those populating an ontology can see the benefits, and those creating or using models/programs based on the ontology can see where the inforamation is coming from.
Equations/formulae can be represented in the ontology, and then sent to the model which can then visualise them and calculate results. A Decision support tool called Vanguard System was used for this.
This screenshot illustrates how a decision support system tree view of the spar (wing part)branch from a wing process and cost model can be created with information translated from an ontology (in Protege) of related taxonomies (sub ontologies), and where necessary from user's selections (e.g. of materials). The tree, including all the default part definition information for the spar, is produced automatically. The buttons in the tree enable choices to be made by the user about materials, consumables, rates, and processes. Branches are created in response to these choices. The values in the branch nodes can then be changed as required.
Results can also then be output to the web for navigation and visualisation, and maybe for interactive web based modelling and visualisation.
Equations/formulae can be represented in the ontology, and then sent to the model which can then visualise them and calculate results. A Decision support tool called Vanguard System was used for this.
This screenshot illustrates how a decision support system tree view of the spar (wing part)branch from a wing process and cost model can be created with information translated from an ontology (in Protege) of related taxonomies (sub ontologies), and where necessary from user's selections (e.g. of materials). The tree, including all the default part definition information for the spar, is produced automatically. The buttons in the tree enable choices to be made by the user about materials, consumables, rates, and processes. Branches are created in response to these choices. The values in the branch nodes can then be changed as required.

Results can also then be output to the web for navigation and visualisation, and maybe for interactive web based modelling and visualisation.
Tuesday, April 14, 2009
Benefits from Enabling End User Programming
My research is to test an approach of using digital technology, to make software and modelling development easier for computer literate end users. This would then enable them to solve problems to help their, and their teams’ work to be more productive. The current problem is that the communication and translation steps required between users, and software developers, and help desk are too many, and too varied, this results in cost, uncertainty, delays, confusion, and confrontation. The solution is for software developers to develop more customisable software that can be customised by end-users.
An example is user’s development of spreadsheets, this indicates user’s willingness to use and develop software to meet their needs, but productivity in spreadsheet development can be poor, as they are difficult to track, and share. More advanced software tools are often not available to users, or take too long to learn. Semantic Web technologies can provide a solution to this by provision of free and customisable, shareable, and fully visualised applications for use in particular sectors. Development of such applications, and their use in industry would be proof of this.
An example is user’s development of spreadsheets, this indicates user’s willingness to use and develop software to meet their needs, but productivity in spreadsheet development can be poor, as they are difficult to track, and share. More advanced software tools are often not available to users, or take too long to learn. Semantic Web technologies can provide a solution to this by provision of free and customisable, shareable, and fully visualised applications for use in particular sectors. Development of such applications, and their use in industry would be proof of this.
Tuesday, November 11, 2008
Economic Models
In order to prove the concept that User Driven Modelling is applicable to domains outside engineering, I'm developing economic models using the same kind of translation technique as I used for engineering models. Models are created in the Vanguard System (http://www.vanguardsw.com/) modelling tool, and can be imported to this from Protégé http://protege.stanford.edu/, via nested SQL queries. Vanguard System performs the calculations necessary for the economic model.
The next step is to visualise the Models in the web browser, and in various languages, to show the concept of multiple language implementations being created from one model. These multiple language implementations all share the same semantics and provide a tree based representation of this semantics.
These are demonstrated at http://www.cems.uwe.ac.uk/~phale/EconomicModels/ModelsVisualised.htm, different representations are provides, so that hopefully at least one representation is accessible to the various web browsers. So far there is an XML, HTML, and Java Applet representation. My intention is to extend both the representation of models and the number and type of models represented, until there is a large grid of models, and representations. Options for extending the representation are to JavaScript, SVG, RSS, RDF, and meta programs, and to increase, the interactivity/editability of the models.
This technique should allow automated creation of many models and language representations of them automatically, using one set of model code outputters/translators.
I'm getting the economic models from Biz/ed - http://www.bized.co.uk/educators/he/spreadsheet/section_1.htm. Eventually I might extend this to other types of models as well as engineering and economic models.
The implementation of the models is at http://www.cems.uwe.ac.uk/~phale/EconomicModels/ModelsVisualised.htm.
The next step is to visualise the Models in the web browser, and in various languages, to show the concept of multiple language implementations being created from one model. These multiple language implementations all share the same semantics and provide a tree based representation of this semantics.
These are demonstrated at http://www.cems.uwe.ac.uk/~phale/EconomicModels/ModelsVisualised.htm, different representations are provides, so that hopefully at least one representation is accessible to the various web browsers. So far there is an XML, HTML, and Java Applet representation. My intention is to extend both the representation of models and the number and type of models represented, until there is a large grid of models, and representations. Options for extending the representation are to JavaScript, SVG, RSS, RDF, and meta programs, and to increase, the interactivity/editability of the models.
This technique should allow automated creation of many models and language representations of them automatically, using one set of model code outputters/translators.
I'm getting the economic models from Biz/ed - http://www.bized.co.uk/educators/he/spreadsheet/section_1.htm. Eventually I might extend this to other types of models as well as engineering and economic models.
The implementation of the models is at http://www.cems.uwe.ac.uk/~phale/EconomicModels/ModelsVisualised.htm.
Monday, June 30, 2008
Visualisation and Interaction for Modelling
Eng and Salustri (2006) outline the role of computers in aiding decision making, and explain that the human mind is the best tool for making decisions. They explain that visualisation systems must help people use the information access capabilities of computers. Eng and Salustri refer to a dimension from “tacit to articulatable” knowledge. So the research for this thesis aims to use the layered Semantic architecture described by Berners Lee et al. (2000) and discussed by McGuinness (2003) relating to this diagram :-
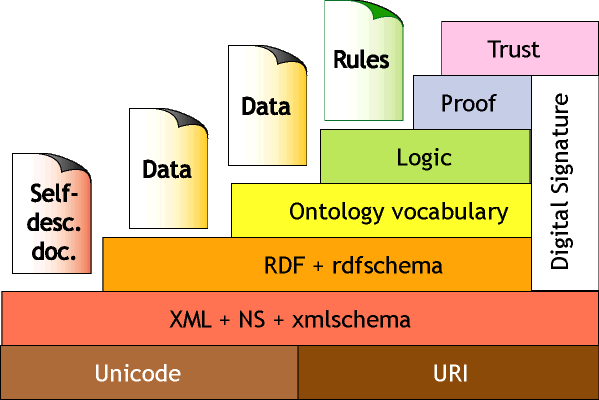
Layered Architecture, sourced from McGuinness (2003) and Berners-Lee (2000)
This improves translatation between the layers to enable human/computer translation. This approach is intended to improve interaction rather than enable computing decision making through artificial intelligence; the emphasis is on decision support for design and manufacture. The detail of this approach and the methodology for automating translation for users is explained in here - http://www.cems.uwe.ac.uk/~phale/#ResearchMethodology. Such techniques as genetic algorithms are outside the scope of this thesis. Instead the emphasis is on clear visualisation, interaction and translation.
This translation code reproduces a taxonomy/ontology and makes it available for modelling/programming systems. This taxonomy/ontology is a copied subset of the main ontology produced as an instance of the main ontology according to model builder choices and for the modelling/programming purposes of that model builder.

Recursive Translation - Automated Copying from ontology to modelling system
Also the translation can link different ontologies/taxonomies together when they are required in order to solve a problem. So the approach is to gather information from ontologies/taxonomies as required for solving a problem as specified by the model builder. This is tested and applied to engineering modelling. An open source approach can be combined with use of open standards ontologies as was advocated by Cheung (2005).
References
Berners-Lee, T., (2000) Semantic Web on XML – Slide 10 [online]. Available from: http://www.w3.org/2000/Talks/1206-xml2k-tbl/slide1-0.html [Accessed 26 June 2008].
Cheung, W. M., Maropoulos, P. G., Gao, J. X., Aziz, H., 2005. Ontological Approach for Organisational Knowledge Re-use in Product Developing Environments. In: 11th International Conference on Concurrent Enterprising - ICE 2005, University BW Munich, Germany.
Eng, N., Salustri, F. A., 2006. "Rugplot" Visualization for Preliminary Design. In: CDEN 2006 3rd CDEN/RCCI International Design Conference University of Toronto, Ontario, Canada.
McGuinness D. L., 2003. Ontologies Come of Age. In: Dieter Fensel, Jim Hendler, Henry Lieberman, and Wolfgang Wahlster, ed. Spinning the Semantic Web: Bringing the World Wide Web to Its Full Potential. MIT Press, 2003 [online]. Available from: http://www-ksl.stanford.edu/people/dlm/papers/ontologies-come-of-age-mit-press-(with-citation).htm [Accessed 26 June 2008].
Layered Architecture, sourced from McGuinness (2003) and Berners-Lee (2000)
This improves translatation between the layers to enable human/computer translation. This approach is intended to improve interaction rather than enable computing decision making through artificial intelligence; the emphasis is on decision support for design and manufacture. The detail of this approach and the methodology for automating translation for users is explained in here - http://www.cems.uwe.ac.uk/~phale/#ResearchMethodology. Such techniques as genetic algorithms are outside the scope of this thesis. Instead the emphasis is on clear visualisation, interaction and translation.
This translation code reproduces a taxonomy/ontology and makes it available for modelling/programming systems. This taxonomy/ontology is a copied subset of the main ontology produced as an instance of the main ontology according to model builder choices and for the modelling/programming purposes of that model builder.
Recursive Translation - Automated Copying from ontology to modelling system
Also the translation can link different ontologies/taxonomies together when they are required in order to solve a problem. So the approach is to gather information from ontologies/taxonomies as required for solving a problem as specified by the model builder. This is tested and applied to engineering modelling. An open source approach can be combined with use of open standards ontologies as was advocated by Cheung (2005).
References
Berners-Lee, T., (2000) Semantic Web on XML – Slide 10 [online]. Available from: http://www.w3.org/2000/Talks/1206-xml2k-tbl/slide1-0.html [Accessed 26 June 2008].
Cheung, W. M., Maropoulos, P. G., Gao, J. X., Aziz, H., 2005. Ontological Approach for Organisational Knowledge Re-use in Product Developing Environments. In: 11th International Conference on Concurrent Enterprising - ICE 2005, University BW Munich, Germany.
Eng, N., Salustri, F. A., 2006. "Rugplot" Visualization for Preliminary Design. In: CDEN 2006 3rd CDEN/RCCI International Design Conference University of Toronto, Ontario, Canada.
McGuinness D. L., 2003. Ontologies Come of Age. In: Dieter Fensel, Jim Hendler, Henry Lieberman, and Wolfgang Wahlster, ed. Spinning the Semantic Web: Bringing the World Wide Web to Its Full Potential. MIT Press, 2003 [online]. Available from: http://www-ksl.stanford.edu/people/dlm/papers/ontologies-come-of-age-mit-press-(with-citation).htm [Accessed 26 June 2008].
Monday, June 16, 2008
User Driven Modelling - Intermediate Benefits
Although User Driven Modelling/Programming is a difficult problem and only partially solved, there are numerous intermediate benefits from the search for this approach. These include better modelling and visualisation of problems, improved interaction with end-users, Semantic Web modelling search and visualisation methods, collaboration to improve modelling, and ways to agree ontology and Semantic Web representations. It was necessary to provide such intermediate benefits as the industrial collaborators had shorter term goals and so required deliverables.
The techniques used helped with progress towards improved interoperability that can aid in all the above areas. These uses and improved interoperability to support them needed to be developed together in an iterative way.
Experienced programmers/software engineers may have many of the problems of end-user programmers whenever they need to use a language/system they are unfamiliar with, or when the language/system they use is updated to a new version. So this means the techniques and approach developed can aid experienced software developers in such circumstances, as well as end-user programmers.
The techniques used helped with progress towards improved interoperability that can aid in all the above areas. These uses and improved interoperability to support them needed to be developed together in an iterative way.
Experienced programmers/software engineers may have many of the problems of end-user programmers whenever they need to use a language/system they are unfamiliar with, or when the language/system they use is updated to a new version. So this means the techniques and approach developed can aid experienced software developers in such circumstances, as well as end-user programmers.
Friday, June 06, 2008
Research Development
It is important to enable changes to the design of the information source and its structure as necessary, even when it contains information. This makes possible continuous improvement of the information and its representation together. Clear visualisation of the structure makes out of date and duplicate information obvious, so it can be changed by the end-users of the information. This provides for maintenance of information quality without necessitating end-users to understand relational database design; though relational databases can still be used for information where the frequency of structural change is less.
The diagrams below shows the way iterative development is used both in this research and in the implementation to ensure that changes can be made systematically as necessary and without disrupting the project.

Research and Development for Thesis
Information about my Research is at - http://www.cems.uwe.ac.uk/~phale/.
Friday, May 30, 2008
Visual Diagrammatic Programming
With visual diagrammatic modelling it was possible to include one model within another as a software component, and demarcate responsibility for building, maintenance, and updating of each model. This was difficult using spreadsheets, and possible with non-visual programming though the link between individual responsibilities and code produce was not as clearly identified, because non-programmers cannot participate in code production. As an example, for cost modelling of an aircraft wing, different experts might build software models for wing spars, wing skins etc, and another expert might be responsible for the overall wing cost model. The wing spar and skins model would then be inserted into the overall wing cost model.
The techniques demonstrated in this thesis can aid progress towards accessing of data held using Semantic Web standards, and also other information that might be locked into particular systems such as databases, spreadsheets and enterprise systems. The translation and de-abstraction approach assists with enabling high level diagrammatic visualisations to be used and translated to computer queries. Programming using Semantic Web technologies can :-
* Assist with translating non-Semantic Web information into Semantic Web information.
* Assist in production of Semantic Web information by end-users by.
* Assist end-users to query non-Semantic Web information.
Further Visualisation Information is at - http://www.cems.uwe.ac.uk/amrc/seeds/Visualisation.htm
End User Programming Information is at - http://www.cems.uwe.ac.uk/amrc/seeds/EndUserProgramming.htm
Thursday, May 22, 2008
Drag and Drop Visual Programming
2 main conclusions resulted from examining the history of end-user computing :-
• Research that created prototype systems for specialist users, school children, and other researchers and programmers, but failed to take make headway in the mass market can be reused with more up to date technology to assist development.
• More pragmatic research that involved creation of tools for the mass market, but which avoided more long term research issues can now be extended.
One mechanism for applying new technologies for use in end-user programming is drag and drop programming.
Repenning (2007) explains the need for enhancements to UML to aid end-user programming. Repenning also argues that "Visual programming languages using drag and drop mechanisms as the programming approach makes it virtually impossible to create syntactic errors." So "With the syntactic challenge being - more or less - out of the way we can focus on the semantic level of End-User Programming." This can make a high level model driven approach to production of better models possible. Rosson (2007) also explains about creation of a web-based drag and drop interface.
Ways that research is pursued in this thesis in order to make User Driven Programming possible are:-
1. Semantic Web and Web 2.0 approach to enabling User Generated Content.
2. User Centric Extensions to UML (Unified Modelling Language) e.g. (Vernazza, 2007) this approach also ventures into 1 and 3).
3. Visual Programming Extensions to spreadsheet type formulae based modelling enabled using approach 1.
Approach 1 is illustrated by Yahoo Pipes (2008) which provides for drag and drop editing of visual components that can combine, sort, and filter RSS data sources in order to automate web application development. This enables modelling of information, and using such diagrammatic programming combined with enabling of calculations would combine these three ways of producing applications. Yahoo Pipes enables creation of modelling applications with Semantic Web information, so this could assist in providing more incentive for provision of Semantic Web information and applications to use it.
So there is considerable overlap between these three approaches and they must be integrated within interdisciplinary research to enable user driven programming. One approach to this is a Semantic User Interface; this is explained in Vernazza (2007). This can enable Drag and Drop programming that combines the benefits of all three research approaches. The important factor is to connect the user interface with the underlying code, so the two share the same structure and users can properly see how their actions can change the actual code. This enables collaborative User-Driven programming.
References
Pipes and Filters for the Internet - http://radar.oreilly.com/archives/2007/02/pipes-and-filters-for-the-inte.html - O'Reilly - Feb 7 2007 - Yahoo!'s new Pipes service is a milestone in the history of the internet. It's a service that generalizes the idea of the mashup, providing a drag and drop editor that allows you to connect internet data sources, process them, and redirect the output.
Repenning, A., 2007. End-User Design. In: End-User Software Engineering Dagstuhl Seminar.
Rosson, M. B., 2007. Position paper for EUSE 2007 at Dagstuhl. In: End-User Software Engineering Dagstuhl Seminar.
Vernazza, L., 2007. Himalia: Model-Driven User Interfaces Using Hypermedia, Controls and Patterns In: IFAC/IFIP/IFORS IEA Symposium - Analysis, Design, and Evaluation of Human-Machine Systems Seoul, Korea - September 4-6th 2007 - International Federation of Automatic Control.
Yahoo Pipes [online]. Available from: http://pipes.yahoo.com/pipes/ [Accessed May 22nd 2008].
This is a Yahoo Pipes example created for the subject of Web 2.0/AJAX -
Yahoo Pipes RSS Feed for Web 2.0 - http://pipes.yahoo.com/pipes/pipe.info?_id=3e30625ebd44f24ff969ae5eef724425
An explanation of how to access and use the pipe created from a web page is at - Code Explanataion/Tutorial Freshblog - Blogger Hacks, Categories, Tips & Tricks - http://blogfresh.blogspot.com/2007/03/pipes-json-and-code-for-your-website.html.
Another article I wrote on Drag and Drop programming is at http://ezinearticles.com/?Drag-and-Drop-Programming&id=671578 and information and examples at http://www.cems.uwe.ac.uk/amrc/seeds/Ajax/ajax.htm#DragandDropProgramming
Monday, April 21, 2008
Visualising Reports
Many organisations produce text based reports from their IT systems. But text based reports don't always show information well enough for good decision making. Automated conversion of these reports into Semantic Web languages could assist greatly with this. So a translation process is required and can be implemented as part of an overall User Driven Modelling/Programming Approach. Once reports are converted to a standardised representation, hierarchical information can be represented as clickable trees and numerical representation as charts.
This makes it possible to customise outputs from existing IT systems and so allows an improvement in readability of information without major changes to the way it's produced. This could provide a large gain at little cost.
Examples of Visualisations are here - http://www.cems.uwe.ac.uk/amrc/seeds/Visualisation.htm#VisualisationExamples.
Chart/Graph type visualisations are here - http://www.cems.uwe.ac.uk/amrc/seeds/PeterHale/Charts/charts.htm.
Friday, March 14, 2008
The SVG (Scalable Vector Graphics Conference) is on this August.
SVG Open 2008 - http://svgopen.org/2008/index.php - 6th International Conference on Scalable Vector Graphics - 26th to 28th August - Nuremberg - Germany - The world conference on SVG will this year take place in the center of Nuremberg. Located in the south of Germany.
I have an SVG page at - http://www.cems.uwe.ac.uk/amrc/seeds/PeterHale/SVG/SVG.htm - with more information.
Saturday, March 01, 2008
PhD Thesis Summary
There are many computer literate people who are experts in a particular domain. This research examines enabling computer literate engineers to model problems in software by minimising the code writing they need to undertake. Software development is difficult for many engineers as they often do not have the time, experience, or access to software development tools necessary to model their problems. Using a combination of modelling via use of formulae (equations) and visualisation of the way these formulae interact it is possible to construct modelling software without requiring code. Crapo et al (2002) explain the need for a methodology for creation of systems to enable more collaborative approaches to modelling by domain expert end-users, and that this combined with visualisation would allow engineers to model problems accurately. This technique of User Driven Modelling/Programming could be widely applicable to any problem that requires linked equations to be represented and tracked, and results from these calculated. While some argue that end-user programming is an insurmountable problem, this problem could be tackled by many researchers co-operating to create specific solutions to different kinds of end user programming problems while also sharing findings, to assist with progress towards a more generic solution.
Crapo, A. W., Waisel, L. B., Wallace, W. A., Willemain, T. R., 2002. Visualization and Modelling for Intelligent Systems. In: C. T. Leondes, ed. Intelligent Systems: Technology and Applications, Volume I Implementation Techniques, 2002 pp 53-85.
More Information is available on my Home Page at - http://www.cems.uwe.ac.uk/~phale/.
Subscribe to:
Posts (Atom)