SWRL
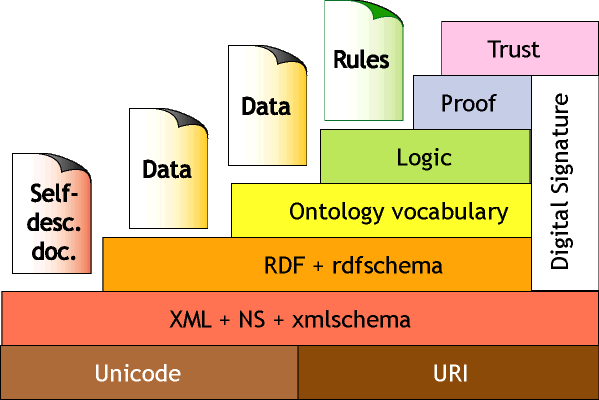
Miller and Baramidze (2005) explain and SWRL (Semantic Web Rule Language). Zhao and Liu (2008) examine the need for sharing product information between partners as a product model, and how agreement through ontologies, Semantic Web, and standards can assist this. Zhao and Liu examine mapping of STEP representations to ontology languages OWL - http://www.cems.uwe.ac.uk/amrc/seeds/PeterHale/RDF/RDF.htm#OWL and SWRL and how this benefits interoperability. Zhao and Liu are encoding STEP rules and executable statements into OWL and SWRL. Zhao and Liu also show a diagram (similar to this one of Berners-Lee) of the position of OWL and SWRL in a stack of standards from XML in the Syntax layer up to OWL/SWRL in the Logic/Rule layer of 'Semantics'.
SWRL (Semantic Web Rule Language) combining OWL and RuleML and its use in modelling will also be investigated. This could be used for formally specifying the construction of equations and rules in a model and the relationships and constraints between items represented in an equation. Miller and Baramidze (2005) explain the SWRL language. An editing facility to model these equations and constraints, so that errors could be prevented, would improve the usability of future visual modelling systems created. Support for SWRL in Protégé and other ontology based systems will assist with the construction of a modelling system with sophisticated editing of rules (Miller and Baramidze, 2005). Miller and Baramidze (2005) examine efforts to develop mathematical semantic representations above the syntactical representations of MathML. SWRL also has standardised arithmetic and comparison operators (Zhao and Liu, 2008). These languages should enable standardisation of the representation of mathematical expressions that relate nodes, and their values and expressions; this would seem to be a difficult problem as it needs a user interface that enables complex mathematical structures to be conveyed by language and/or diagrammatic visualisation.
References
Miller, J A., Baramidze, G., Simulation and the Semantic Web - 2005. - Proceedings of the 2005 Winter Simulation Conference.
Zhao, W. and Liu, J.K. 2008. OWL/SWRL representation methodology for EXPRESS-driven product information model Part I. Implementation methodology, Computers in Industry - Article in Press, Corrected Proof - Abstract - This paper presents an ontology-based approach to enable semantic interoperability and reasoning over the product information model. The web ontology language (OWL) and the semantic web rule language (SWRL) in the Semantic Web are employed to construct the product information model. The traditional modeling language called EXPRESS is discussed. The representation methodology for EXPRESS-driven product information model is then proposed. The key of the representation methodology is mapping from EXPRESS to OWL/SWRL. Some illustrated examples are presented. - Keywords - Product information model; OWL; SWRL; EXPRESS; Ontology representation. Zhao and Liu (2008) are encoding STEP rules and executable statements into OWL and SWRL.
RuleML
The research of the Rule Markup Initiative is explained here. Rules for the Web have become a mainstream topic since inference rules became important in E-Commerce and the Semantic Web, and since transformation rules were put into practice for document generation from a central XML repository. Rules have continued to play an important role in artificial intelligence, knowledge-based systems, and for intelligent agents. This is now combined with standardisation in XML/RDF enabling use of declarative rules for web services. The Rule Markup Initiative has taken steps towards defining a shared Rule Markup Language (RuleML), enabling both forward (bottom-up) and backward (top-down) rules.
Reference
RuleML - The Rule Markup Initiative http://www.ruleml.org/.
Representation of Equations
Gruber (1993) examines how equations and quantities can be represented in an ontology. Kamareddine et al. (2004) examine how mathematics can be represented in order to make it easier for people to enter well-formed mathematical expressions.
Shim et al. (2002) examine translation from a users' model to equations and explain "converting a decision-makers' specification of a decision problem into an algebraic form and then into a form understandable by an algorithm is a key step in the use of a model". For a practical example the figure below explains the concept for a simple example of the representation of the equation E=MC2. This relationship can be defined by the user. Here this is achieved using an ontology tool (Protégé), and this definition can be read directly by Decision support software (Vanguard Studio) that can visualise the information and colour code it. For a more complex example a higher level user interface would be required to enable a user to define the problem, and a translation step to the computer readable model. Units have been left out as the type of equation used and values in it are not important to the concept. The software can translate the source model into a program and calculate results. The result program is then translated again into a result model defined using open standard languages such as XML, and Java for human friendly visualisations viewable as web pages/diagrams.

Translation Process - Equations
References
Gruber T. R. 1993, Toward Principles for the Design of Ontologies Used for Knowledge Sharing - http://www2.umassd.edu/SWAgents/agentdocs/stanford/onto-design.pdf - In Formal Ontology in Conceptual Analysis and Knowledge Representation, edited by Nicola Guarino and Roberto Poli, Kluwer Academic Publishers, in press. Substantial revision of paper presented at the International Workshop on Formal Ontology, March, 1993, Padova, Italy. Available as Technical Report KSL 93-04, Knowledge Systems Laboratory, Stanford University.
Kamareddine, F., Maarek, M., Wells, J. B, 2005, Toward an Object-Oriented Structure for Mathematical Text - http://www.macs.hw.ac.uk/~jbw/papers/Kamareddine+Maarek+Wells:Toward-an-Object-Oriented-Structure-for-Mathematical-Text:MKM-2005.pdf - Mathematical Knowledge Management, 4th Int'l Conf., Proceedings, LNCS. Springer-Verlag.
Quint, V., Vatton, I., 2004. Techniques for Authoring Complex XML Documents - http://wam.inrialpes.fr/publications/2004/DocEng2004VQIV.html - DocEng 2004 - ACM Symposium on Document Engineering Milwaukee October 28-30 - This paper reviews the main innovations of XML and considers their impact on the editing techniques for structured documents.
Quint, V., Vatton, I., 2005. Towards Active Web Clients - http://wam.inrialpes.fr/publications/2005/DocEng05-Quint.html - DocEng 2005 - ACM Symposium on Document Engineering - 2-4 November 2005 - Bristol, United Kingdom. - Recent developments of document technologies have strongly impacted the evolution of Web clients over the last fifteen years, but all Web clients have not taken the same advantage of this advance. In particular, mainstream tools have put the emphasis on accessing existing documents to the detriment of a more cooperative usage of the Web. However, in the early days, Web users were able to go beyond browsing and to get more actively involved.
Shim, J.P., Warkentin, M., Courtney, J. F., Power, D J., 2002, Past, present, and future of decision support technology - Decision Support Systems - Volume 33, Issue 2 , June 2002, Pages 111-126.
MathML is a specification for describing mathematics as a basis for machine to machine communication. It provides a way of including mathematical expressions in Web pages. This is explained at World Wide Web Consortium Math Home (2008). There is support for creation and editing of MathML documents in Amaya (Amaya, 2008), (Quint and Vatton, 2004 and 2005).
MathML and semantics built on this could assist in the process of translating equations/formulae into code by providing an open representation of functions as XML (eXtensible Markup Language). Functions entered by the model developer can then be translated to this open representation and translated to programming languages and/or read by programming languages.
Miller and Baramidze (2005) examine efforts to develop mathematical semantic representations above the syntactical representations of MathML.
References
Amaya - http://www.w3.org/Amaya/ - Welcome to Amaya - W3C's Editor/Browser - Amaya is a Web editor, i.e. a tool used to create and update documents directly on the Web. Browsing features are seamlessly integrated with the editing and remote access features in a uniform environment. This follows the original vision of the Web as a space for collaboration and not just a one-way publishing medium.
Miller, J A., Baramidze, G., Simulation and the Semantic Web - 2005. - Proceedings of the 2005 Winter Simulation Conference.
World Wide Web Consortium (W3C) Math Home, 2008. What is MathML? http://www.w3.org/Math/Overview.html.
Links
Coq proof assistant - http://coq.inria.fr/ - Coq is a formal proof management system: a proof done with Coq is mechanically checked by the machine.
End User Programming for Scientists: Modeling Complex Systems - http://drops.dagstuhl.de/opus/volltexte/2007/1077/ - Andrew Begel - Microsoft Research - In: End-User Software Engineering - Dagstuhl Seminar - Summary - http://www.dagstuhl.de/en/program/calendar/semhp/?semnr=2007081 - Margaret M. Burnett, Gregor Engels, Brad A. Myers and Gregg Rothermel - From 18.01.07 to 23.02.07, the Dagstuhl Seminar 07081 End-User Software Engineering was held in the International Conference and Research Center (IBFI), Schloss Dagstuhl.
EquMath.Net - http://equmath.net/ - EquMath is resource for math lessons from Algebra to Differential Equations!.
Equplus - http://equplus.net/ - Science and Math Equations.
Mathematica - http://www.wolfram.com/ - Wolfram Research.
Mathematical Functions - Interactive Graph - http://www.richtann.com/2dExamples/graph.html - Richard Tann UWE - An Example using Actionscript to model functions and dynamically redraw according to user interaction.
MathLang: experience-driven development of a new mathematical language - http://citeseer.ist.psu.edu/kamareddine04mathlang.html - F. Kamareddine, et al., 2004 - Abstract: In this paper we report on the design of a new mathematical language and our method of designing it, driven by the encoding of mathematical texts. MathLang is intended to provide support for checking basic well-formedness of mathematical text without requiring the heavy and dicult-to-use machinery of full type theory or other forms of full formalization. At the same time, it is intended to allow the addition of fuller formalization to a document as time and e ort permits.
MathWeb - http://www.mathweb.org/ - MathWeb.org supplies an infrastructure for web-supported mathematics.
Mizar Project - http://mizar.org/project/ - The Mizar project started around 1973 as an attempt to reconstruct mathematical vernacular in a computer-oriented environment.
OMDoc.org - http://www.omdoc.org/ - OMDoc.org: The OMDoc Portal - OMDoc is a markup format and data model for Open Mathematical Documents. It serves as semantics-oriented representation format and ontology language for mathematical knowledge.
OpenMath - http://www.openmath.org/ - OpenMath is a new, extensible standard for representing the semantics of mathematical objects.
Richard Tann UWE - http://www.richtann.com/2dExamples/graph.html - Mathematical Functions - An Example using Actionscript to model functions and dynamically redraw according to user interaction.
Toward an Object-Oriented Structure for Mathematical Text - http://www.macs.hw.ac.uk/~jbw/papers/Kamareddine+Maarek+Wells:Toward-an-Object-Oriented-Structure-for-Mathematical-Text:MKM-2005.pdf - Kamareddine, F., Maarek, M., Wells, J. B, 2005, Mathematical Knowledge Management, 4th Int'l Conf., Proceedings, LNCS. Springer-Verlag.
SRML
SRML - Simulation Reference Markup Language - http://www.w3.org/TR/SRML/ - W3C Note 18 December 2002.
SRML case study: simple self-describing process modeling and simulation - http://ieeexplore.ieee.org/xpls/abs_all.jsp?arnumber=1371486 - Reichenthal, S.W. Boeing, Anaheim, CA, USA; 2004, Simulation Conference, 2004. Proceedings of the 2004 Winter - Volume: 2, pp 1461- 1466 - ISBN: 0-7803-8786-4.










{kind=link}